



In this paper, we present a general framework to scale graph autoencoders (AE) and graph variational autoencoders (VAE).
This framework leverages graph degeneracy concepts to train models only from a dense subset of nodes instead of using the entire graph. Together with a simple yet effective propagation mechanism, our approach significantly improves scalability and training speed while preserving performance.
We evaluate and discuss our method on several variants of existing graph AE and VAE, providing the first application of these models to large graphs with up to millions of nodes and edges.
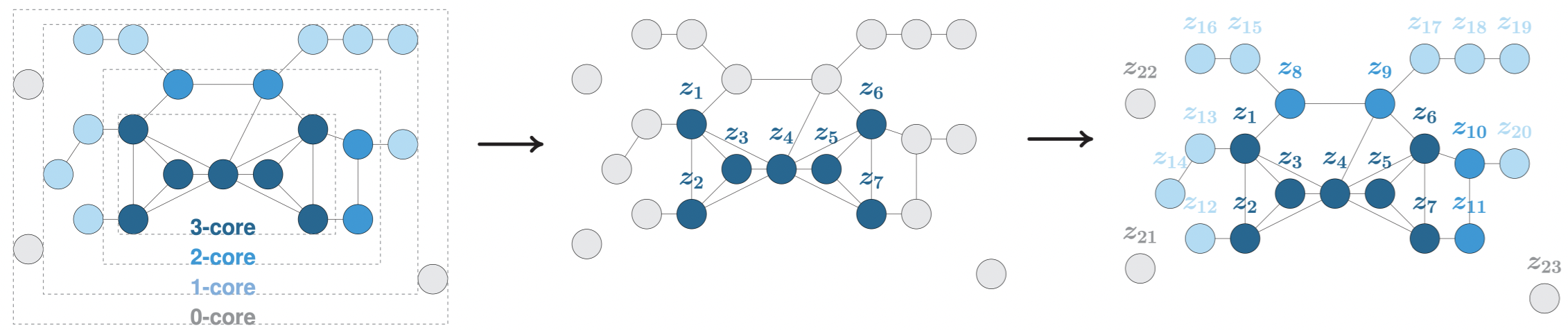
We achieve empirically competitive results w.r.t. several popular scalable node embedding methods, which emphasizes the relevance of pursuing further research towards more scalable graph AE and VAE.
This paper has been published in the proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI 2019).


