



A new way to look at an artist: From lyrics to wordclouds (Christmas Special!)


One thing we like at Deezer is music. And another thing we are quite fond of is data. So when it comes to doing data stuff on music material, no need to tell you we’re all pretty excited!
As you may or may not know, one of the cool things about Deezer product is that you can play some songs with lyrics on (there you go karaoke nerds!). That’s why we thought we could probably give a go to a small and quick lyrics analysis.
Lyrics mining and analysis was actually something we had been willing to have fun with for quite a while. So after looking a bit around to document ourselves about the subject, we thought: word clouds!
NB: If you’re only interested in the results, go straight to the end of the article!
Data Structure
First thing first, we should tell you a bit more about how our lyrics data was structured. It was actually pretty convenient and nice to deal with as we basically had to work with two main columns: the song id one and the lyrics text one.
- sng_id: the column we use as a key to join our lyrics table to other tables in order to fetch data based on song titles or ids, artists names, etc. depending on what we were interested in (but more on that later).
- lyrics_text: this column basically contains the lyrics text of each song in a string format.
Thanks to the sng_id variable and to the Deezer catalog information, we could have performed lots of different song aggregations.
Creating word clouds on a song level would for sure haven’t been really interesting as the number of words would have been too small to create a substantial word cloud.
We would probably have faced the same issue doing it on an album level considering the small number of songs there is per album.
The music genre level, however, would definitely have been interesting. But considering our data, each music genre would have been a blend of French, German, English, etc. songs. And as most text mining packages work well with English texts, we would have had to translate all the non-English songs to English. Since we didn’t want to distort these songs lyrics by translating them to English, the most efficient and accurate solution to go with seemed to be the artist one: enough songs for most of them, songs of the same language, etc.
We then needed to pick an artist we were interested in and for who we had enough songs to analyze.
Lots of cool songs, lots of cool lyrics, we thought… The Beatles. So we got the corresponding lyrics texts data and stored it in a variable we called data (oh how original — I know).
If you need data to run the script on, just build a small .csv file with lyrics from the artist you’re interested in. A single column containing the lyrics and pandas’ read_csv function should do the job!
Imports Time
Pretty basic and classical imports basically!
Except maybe for NLTK (Natural Language Toolkit) which, as its name suggests it, will help us dealing with text. It provides several super cool functions such as lemmatizer, tokenizer and much more that we will use during our data cleaning step.
The WordCloud and ImageColorGenerator imports are the ones that will allow us to build our word cloud. Both of them were developed by Andreas Mueller. WordCloud is the function that will allow us to create the word cloud (you’ll be able to find the corresponding script right here) and ImageColorGenerator is the one enabling us to generate the word cloud colors based on the ones of the original image (script right there).
Clean That Data!
Get the data: done. Import the right packages: done. Next: data cleaning! We first needed to operate some preliminary changes to have clean data to work with.
We therefore converted lyrics text to lowercase, decoded the whole thing & removed backslashes that for some reason had appeared during the row[‘lyrics_text’] step.
We then defined all_lyrics as the concatenation of all the songs lyrics texts thanks to a for loop because that’s how the input should look like before being inserted in the wordcloud package.
Since the wordcloud package we are using is quite comprehensive, it actually contains a lot of functions that allowed us to quickly end up with a quite satisfying word cloud just by applying the wordcloud class on all_lyrics: no need to remove punctuation, stopwords (words such as “I”, “you”, etc.) or to stem the whole thing as the package does most of it on its own.
For instance, have a look at the top 10 words of the all_lyrics Beatles data:
“The”, “you”, “I”, “to”, etc.: not that interesting huh. Yet, look at the word cloud we would get without further coding (but the one behind the word cloud generation script obviously):
Still, if you carefully look at the word cloud, you’ll see that the words aggregation is not optimal yet as there are still some words that do not seem to have been perfectly lemmatized: “said” for instance (located in the “o” of “love”) wasn’t recognized as belonging to the “say” root.
This is no biggie, but we could actually consider that this might distort the final results as “said” for instance is not considered the same as “say”, and “waiting” isn’t aggregated along with “wait”. When they actually — well, in our opinion — should.
This is precisely why we decided to go a bit further and to investigate in order to find a way to lemmatize those verbs properly and to aggregate our data in the best possible way.
Therefore… On to tokenization.
For those who don’t know, tokenization is a very common practice in text mining that consists in breaking up a text into words in order to proceed to various operations on tokens that we might not have been able to apply on a string.
Tokenizing all_lyrics then allowed us to properly start the lemmatizing step and therefore to remove verbs terminations we talked about at the beginning of this part.
As a reminder, lemmatization is the process of retrieving a word canonical form thanks to algorithmic processes.
If you look at the word cloud package comments, you’ll see that the only text normalization applied there, is a plural normalization, meaning the algorithm only remove plural “s” to words. What bothered us was mainly verbs termination (and not only third person “s”), so we tried several lemmatizers with the aim of finding one that would remove “ing”, “ed” from verbs and basically retrieve the verb most basic form.
Among Porter, Lancaster Stemmers and much more, WordNetLemmatizer appeared to be the most satisfying one. We basically characterized every single token as a verb and then let our WordNetLemmatizer do the rest, meaning remove every verb termination.
“belongs” became “belong”, “gone” went “go”, “feeling” became “feel” (we deliberately chose to transform potential “ing” nouns in verbs), “changed” became “change”, and so on.
Whether you set the normalize_plural parameter to “True” or “False” during the word cloud generation afterward does not change anything since all the plural “s” should have already been removed thanks to this lemmatizer.
If you go back to the list of tokens that was previously screenshotted, you might note that tokenizing all_lyrics led to two main issues that we faced in two different ways:
- Words such as “i’m”, “you’re” or “can’t” were weirdly tokenized and were cut like “i” and “‘m”, “you” and “‘re” or “ca” and “n’t” thus leading these pieces of words to be inserted in the word cloud since they were not present in this shape in the stoplist. We therefore thought about removing every 1 or 2 letters words. This, however, meant we had to give up on words like “oh”, “ah”, and so on. But a choice had to made… And that’s the story of how we said goodbye to “n’t”, “‘ll”, and this other type of folks.
- Another problem we had following all_lyrics tokenization was related to English slang: “gonna”, “wanna”, etc. had been tokenized as “gon” and “na” and then rejoined as “gon na”. As these kind of words are not that many we decided to simply manually replace them with the right corresponding stem.
Et voilà! As the word cloud package removes punctuation and stopwords on its own, we then only needed to apply the wordcloud class to lyrics_abrev to get our word cloud!
Generate that word cloud!
Hold on, upcoming steps are the coolest. You first need to define what your word cloud mask will look like (the shape and color your word cloud will take basically). To do so, we created two files: the “music genre” one containing generic music genre related pictures and another one (the “other images” file) with more artist related pictures. If you need to, you can use the small mask repository we created on GitHub.
Then, you just need to adjust your word cloud parameters: its width, its height, the margin, the font, the maximum and the minimum font sizes, the background color, and many more (if you’re interested in the comprehensive parameters list, have a look at the wordcloud.py script on A. Mueller’s GitHub).
And… it’s finally time to generate your word cloud from your last lyrics variable. We went for the colorful version and, therefore, also used the ImageColorGenerator we talked about earlier.
Eventually, we used matplotlib to display the word cloud & defined a path to store all of our brand new word clouds.
Playtime!
I finally tested the script on several artists that I globally grouped by music genre, and here are the results. Enjoy!
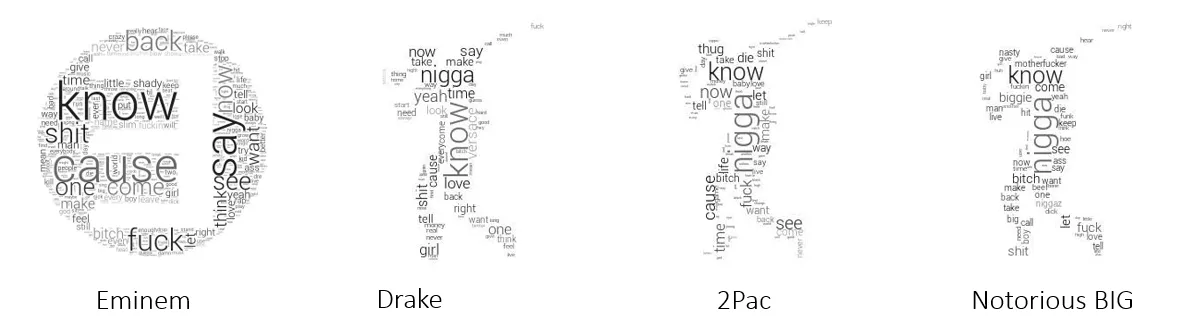





So that’s about it for us!
We’d love to get your feedbacks about the methods we used, the word clouds, and so on, so feel absolutely free to comment or to get in touch with us if you have any suggestions, questions or advice!


