



On the occasion of the PHP Tour 2017 -a French event on PHP programming- that takes place in Nantes on May 18–19, here is a post on Content Import that is being handled internally using PHP.
Deezer is a partner of the PHP Tour 2017 and several of our developers will attend the event. They will enjoy some of the technical sessions, discuss our projects on our stand and offer attendees to take part in coding challenges.
In the meantime, let’s read about content import at Deezer!

A system to import content in PHP: why?
Let’s talk a bit about history. Deezer was originally Blogmusik.net, a music download platform founded in 2007 by Daniel Marhely and developed entirely in PHP.
“Benefits” …
In 2007, there were only few developers within Deezer’s teams. It was then even more important to share knowledge and have common modules to handle the website, as well as the processing and insertion of data into the database. Therefore managing the import of data in PHP was an undeniable advantage.
Also we did not need a developer dedicated to a different stack to process the data. This way, a developer working on the website could also take care of the import part and vice versa. PHP was already very popular so it was always easy to find documentation and answers in case of a problem.
One other advantage was that devops had only one technological stack to deploy. A very precious time saver.
… and “drawbacks”
PHP was not made for pure backend processing. The language is not compiled but rather web-oriented; performance in the case of large data processing, disk access and parallelization is not as good as what we could get from a pure backend and processing oriented language.
PHP was not natively multi-threaded. Now there is a “native” library but we are still far from the simple and effective integration that other languages can offer.
PHP was and remains very web oriented. As a consequence, there are many libraries to facilitate web development … but far fewer for backend development. Libraries regularly appear according to the needs of their authors but some teams do not have time to undertake the development of these tools.
Managing large volumes of data in PHP
How can we overcome these “drawbacks”?
Parallelize script execution
Even if PHP is not multi-threaded, it is possible to launch the same script several times with different arguments in order to process various data in parallel.
The only disadvantage compared to multi-threading: memory resources are not shared but it can be solved with a cache system.
Do asynchronous processing
A script is executed procedurally: if a task is blocked, the script waits for it to be completed then carries on. However, if the result of the script is not needed to continue, it is better to start this processing asynchronously and not block the script execution.
Parallelization
We receive an always increasing volume of metadata from our providers so it is vital that we go always faster to process them in order to put new albums live on time.
We chose to parallelize the scripts and have a master script that coordinates them all. Its role is crucial, it has to be effective but simple:
- Check if there are things to do
- Run one or more scripts (if necessary) with the appropriate parameters to handle the heavy processing
In order to facilitate the launch and monitoring of these scripts, we converted them into Daemons. This way it is very easy for devops to manipulate the master scripts.
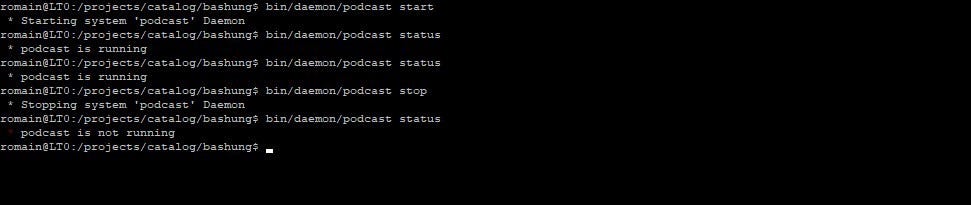
To avoid overloading backend servers, the scripts also need to regulate the load.
- If there is nothing to do, no subscript is started
- If the number of elements to be processed increases, the master script launches a number of subscripts in parallel to cope with the workload
Last advantages of a master / subscripts system: the memory is freed once the script is finished and we prevent memory leak and crashes.
We also set up a “server” script to receive commands to execute through a socket system. The advantage here is to have a “server” on each backend machine and therefore to distribute the load on different machines.
Asynchronous processing
The aforementioned command server also allows asynchronous execution.
The script that sends the request to the server is only waiting for the message to be accepted by the server. This prevents the blocking of the script execution while triggering a command that will restart a script for an additional processing.
Finally, in order to better distribute the load on the various stages of the data processing, we have implemented a relatively simple tail system.
Currently, it is used to put the elements to publish from the Import Database to the Shared Database used by other teams and the website. This makes it possible to separate the publication by type of entities to publish (albums, podcasts, radios …) on different scripts (via the system master script described above).

Thus we benefit from parallelization and load adaptation.
Ideas for the future
At the moment our queuing system is reserved to publication but the need to trigger tasks asynchronously becomes more and more important and frequent.
Also, we are currently experiencing a limitation in the addition of asynchronous tasks. For example, we would like to add an item to the queue that would be processed at a certain date / time, especially to deal with cache desynchronization between Europe and America, which sometimes occurs and is linked to a delay in SQL replication.
We will for instance need to update the cache, but only a few seconds or minutes after queuing, not immediately.
Finally, we are in the process of completely refactoring our PHP architecture to make it more SOLID while keeping a certain flexibility: injection of dependencies, use of services, creation of internal API to isolate our code and our data, etc.
In short, the future is full of promises and complexity to our greatest delight!
Pourquoi un système d’import du contenu en PHP ?
Parlons un peu d’histoire. Deezer était à l’origine Blogmusik.net, une plateforme de téléchargement de musique fondée en 2007 par Daniel Marhely et développée entièrement en PHP.
Des “avantages”…
En 2007, le nombre de développeurs au sein des équipes de Deezer était réduit. Il était donc plus profitable de partager les connaissances et d’avoir des briques communes pour l’affichage du site et le traitement et insertion des données en base de données. Par conséquent, l’import des données en PHP était ici un avantage indéniable.
Un autre avantage était de ne pas avoir besoin d’un développeur dédié à une techno différente pour traiter ces données. Ainsi, un développeur du site pouvait également s’occuper de la partie import et vice-versa. PHP étant très populaire, il a toujours été très facile de trouver de la documentation et des réponses en cas de problème.
Enfin, cela ne nécessitait pas des devops d’avoir des connaissances pour déployer un environnement pour une techno différente. Un gain de temps très précieux.
… Et des “inconvénients”
PHP n’était pas pensé pour du traitement backend pur. Le langage n’étant pas compilé mais plutôt orienté web, les performances pour du traitement de données volumineuses, accès disques et parallélisation sont moindres qu’un langage orienté pur backend et traitement.
PHP n’était pas nativement multi-threadé. Il existe aujourd’hui une librairie “native” mais on est encore loin d’une intégration simple et efficace comme avec d’autres langages informatiques.
PHP était et reste très orienté Web. Par conséquent, on trouve de nombreuses librairies pour faciliter le développement Web… mais beaucoup moins pour du développement backend. Certaines librairies apparaissent régulièrement en fonction des besoins de leurs auteurs mais certaines équipes n’ont pas de temps à allouer au développement de ces outils.
Gérer des gros volumes de données en PHP
Quelles sont les pistes pour répondre à ces “inconvénients” ?
Paralléliser l’exécution des scripts
En effet, même si PHP n’est pas multi-threadé, il est tout à fait possible de lancer plusieurs fois un même script avec des arguments différents pour traiter en parallèle des données différentes.
Seul désavantage par rapport à du multi-threading : le non-partage des ressources mémoires, que l’on peut résoudre par un système de cache.
Faire du traitement asynchrone
Un script est exécuté de manière procédurale : si un élément est bloquant, le script attend que cet élément soit terminé pour continuer. Cependant, si le script n’a pas un besoin impératif du résultat du traitement, autant lancer ce traitement de manière asynchrone et ne pas bloquer l’exécution du script.
La parallélisation
Confronté à ce problème de traitement d’un grand nombre de livraisons de méta-data par les maisons de disque, et afin de garantir qu’un nouvel album arrive bien en temps et en heure sur Deezer, il est vital que nous puissions traiter au plus vite ce volume en constante augmentation.
La solution retenue a été de paralléliser les scripts. Nous fonctionnons donc avec un script master, qui ne fait que lancer les scripts à paralléliser. Son rôle étant crucial, il est important qu’il soit efficace, même si limité en terme de technicité :
- Vérifier s’il y a des choses à faire
- Lancer un ou plusieurs scripts (si nécessaire) avec les paramètres appropriés, chargés de faire les traitements lourds.
Afin de faciliter le lancement et le monitoring de ces scripts, une surcouche Bash Linux est implémentée afin d’en faire des Daemons. De cette façon, il est très aisé pour les devops de manipuler ces scripts masters.

Pour éviter une surcharge des serveurs backend, ces scripts doivent aussi réguler la charge.
- S’il n’y a rien à faire, aucun sous-script n’est lancé.
- Si le nombre d’éléments à traiter augmente, le master script lance en parallèle un certain nombre de sous-scripts pour faire face à la charge de travail.
Derniers avantages d’un système master / sous-scripts : la mémoire est libérée une fois le script terminé et donc on limite la fuite mémoire et le plantage du script.
Nous avons également mis en place un script “serveur” chargé de recevoir des commandes à exécuter à travers un système de sockets. L’avantage est de pouvoir avoir un “serveur” par machine backend et donc de répartir la charge sur différentes machines.
Le traitement asynchrone
Le serveur de commande mentionné précédemment permet aussi d’avoir une exécution asynchrone.
Le script qui envoie la demande au serveur n’attend que l’acceptation du message par le serveur. Cela permet donc de ne pas bloquer l’exécution du script, tout en déclenchant une commande qui va relancer un script, pour un traitement annexe.
Enfin, afin de mieux répartir la charge sur les différentes étapes du traitement des données importées chez Deezer, nous avons mis en place un système de queue relativement simple.
Actuellement, il nous sert à mettre des éléments à “publier” de la base de données d’import vers la base de données accessible au reste des équipes & du site. Cela permet de séparer la publication par type d’entités à publier (albums, podcasts, radios…) sur des scripts différents (via le système master script décrit précédemment).

Nous bénéficions ainsi de la parallélisation et de l’adaptation de charge.
Les pistes pour le futur
Pour le moment, notre système de queue est réservé à la publication mais nous avons de plus en plus besoin de déclencher certaines tâches de manière asynchrone, et non uniquement sur la publication.
De plus, nous rencontrons actuellement une limitation sur l’ajout de tâches asynchrones. Nous souhaiterions par exemple ajouter un élément dans la file d’attente mais pour un traitement à partir d’une certaine date / heure; ceci notamment pour faire face à un souci de désynchronisation de cache entre l’Europe et l’Amérique qui se produit parfois et est lié à un retard de réplication SQL.
Nous devrons par exemple effectuer une mise à jour du cache, mais seulement quelques secondes ou minutes après la mise en queue, pas immédiatement.
Enfin nous sommes en train de revoir entièrement notre architecture PHP pour la rendre plus SOLID, tout en gardant une certaine souplesse : injection de dépendance, utilisation de services, création d’une API en interne pour isoler notre code et nos données, etc.
Bref, l’avenir s’annonce plein de promesses et de complexité, pour notre plus grand bonheur !



