




Matching albums from one source to another is a recurring task at Deezer. Several reasons require platforms to do this such as partnerships, when two companies merge or compare their catalog and metadata enhancement. This also occurs when a platform refers to another source like Wikipedia or Musicbrainz for additional crowd sourced information.
Unique identifiers like the UPC (Universal Product Code) is the best common ID to be found in catalogs and is still widely used. However this ID comes from a brick-and-mortar realm, affixed to the barcode usually scanned by a cashier, and is not consistently found with digital-only releases. As often is the case, the title of the album and artist name can be used to match albums from different sources, with known caveats like spelling discrepancies, multi-artist releases or homonym titles. The image comparison aims to enhance this metadata matching by leveraging image fingerprinting.
The immediate advantage of album covers is their coherence from one source to another. When any cover is given, no matter what the quality there are often a lot of similarities and they generally stem from one official source. The worst material provided can include photographs or scans of CD/vinyl cover with possible truncations, empty spaces and color changes. Hopefully image fingerprints are robust enough to detect such alterations. A fingerprint of a given image (like a scan or photograph) can be considered close enough to the official counterpart by a robust image fingerprint technique.

During the 2002 International Conference on Image Processing, H. Chi Wong, Marshall Bern and David Goldberg published a paper named An image signature for any kind of image. Developer ascribe implemented this paper in Python in a library called image-match, including an Elasticsearch and a Mongo backend to store and retrieve documents following Wong et al. algorithm. This library is particularly helpful and has been at the core of our experimentations.
In the Wong et al. approach, a signature of the image is computed from a grid where each grid point is compared to its eight neighbors according to its average gray level:
“The result of a comparison can be much darker, darker, same, lighter or much lighter, represented numerically as -2, -1, 0, 1 and 2.”
Thus, an image is signed as an array of values (a vector) from -2 to 2, such as [0, 0, -2, -1, 2, 2, 1, 0]. Comparing an image to another boils down to computing a distance between their two vectors. The result is a value between 0.0 and 1.0, where 0.0 means both vectors are exactly the same.
This method is sufficient to compare two images, but when it comes to looking for image similarities in a big corpus, one needs another representation. The signature is sorted into a list of words (in fact integers) that can be “speedily indexed and matched”. The commented source code here is self-explanatory. Each image can then be stored and indexed by a new list of integers, such as [3141592, 6535897, 93238462, 643383, 27950288]. Two images sharing one or several words are likely to be similar. Their similarity is then computed by their signature’s distance.
“This method solves the problem of nearest-neighbor search in high dimensions by finding exact matches in a number of lower-dimensional projections.”
Implementing this technique to match external albums to our Deezer catalog implies two important steps:
- To fingerprint our entire cover catalog
- To determine the similarity threshold
Fingerprinting the entire Deezer catalog took us around two days, parallelizing the task 6 times. The task consists in computing the signature and the words for each image, as well as storing them in the backend — Elasticsearch in this case. Some metadata is also added, like the album ID, the album title and the artist name, that will be useful for later development.
The threshold in Wong et al. is normalized:
“The parameters […] are chosen so that any vector v within normalized distance of .6 is sure to match on at least one word”.
Given the high volume of covers — around 8 million — .6 seems too high a limit. To refine this threshold, an annotation campaign was held within our team (R&D). Using a threshold of .4, covers from Musicbrainz were matched to Deezer. A simple page allowed us to annotate if the matches were considered legitimate or not.

From this campaign, the following data was collected:
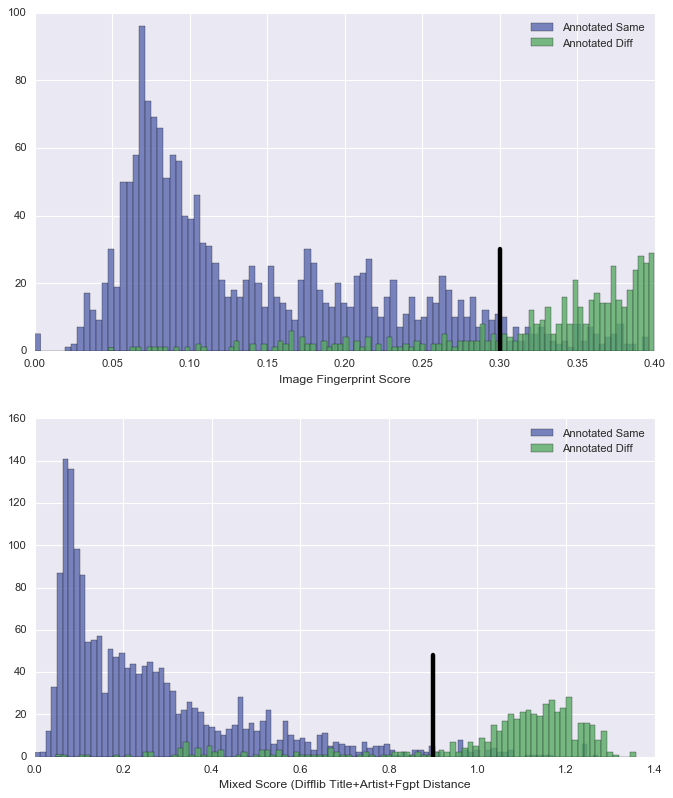
When analyzing the false positive and false negative, two specific problems were blindingly obvious. We named them:
- The collection issue
- The single issue
In the collection issue, several covers are the same or similar enough to be considered as the same image. However, they do not represent the same album. Look at the following:

Another effect of the collection issue is the presence of a small icon on the cover, like a “Parental Advisory” icon or a “Deluxe” icon. The original cover and its iconed counterpart can be seen as belonging to the same collection of releases.

On the other hand, in the single issue, the cover is exactly the same but the music content is not, usually (but not only) a single release and its album counterpart:

The collection and single issues give good false positive examples. False negative results include image distortions confusing the Wong et al. approach. One of them is the rotation. Image-match implements 90, 180 and 270-degree transformation by altering and requesting each image four times (at a high cost), but other angles are not covered. The Wong et al. approach is also very sensitive to truncated image, confusing the brightness comparisons.

Unfortunately, there is no easy way to avoid false positives (single and collection issues). However, there is an approach on top of sole image fingerprinting to match more efficiently two albums, by adding metadata in the comparison. Instead of just comparing the images, it is possible to compare the titles and the main artist when the metadata is available. We expect to disambiguate the collection and single issues, where the title and artist are supposedly highly discriminating.
The text comparison is based on a difflib algorithm (a Python library), self-described as:
“The basic algorithm predates, and is a little fancier than, an algorithm published in the late 1980’s by Ratcliff and Obershelp under the hyperbolic name “gestalt pattern matching.” The idea is to find the longest contiguous matching subsequence that contains no “junk” elements”
The image-match backend implements the storage of metadata in a JSON dictionary. Thus, an image in Elasticsearch (for instance) is an aggregation of three main parts: the signature, the words and metadata.

The following graph shows that considering both the image and metadata improves the matching. From an annotated dataset, we run these five matching techniques:
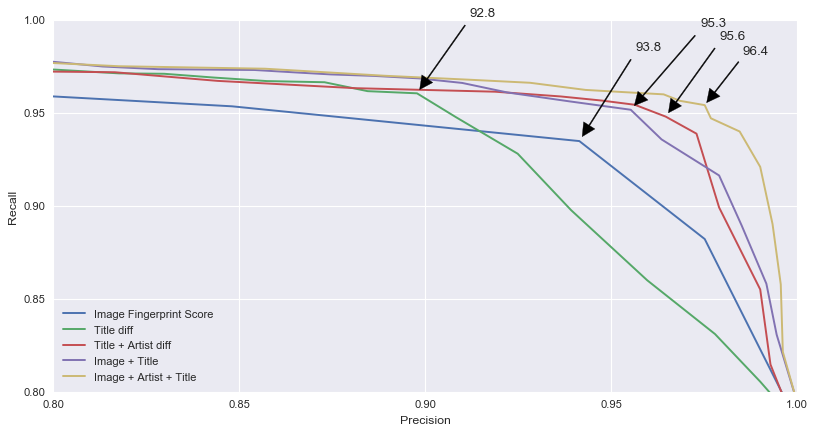
The image fingerprint score by itself obtained the worst results (93.8) compared to metadata only, especially Title + Artist (95.6). However the two combined raised the F1 score to 96.4. This analysis helped us to determine thresholds for each matching technique.
One might think that such an approach eliminates all the caveats described previously. However, it can also reveal new false positives, which are less numerous than the ones observed earlier. In particular, when the image is close enough to validate a match, the text comparison can eliminate the option because of potential discrepancies from one source to another.

To conclude, the cover image comparison led us to build a better matching algorithm, and an option to match albums in situations where the metadata is not available. Image-matching proved to us in an internal hackathon earlier this year that it can be legitimately used to match photographs or scans of a personal catalog to an official catalog, opening new ideas for features. The main condition is that the target catalog must maintain all cover fingerprints. Our experience with the Deezer and Musicbrainz catalog proved that it is reasonably feasible as part of a catalog ingestion and maintenance, in the same fashion as storing the audio fingerprintings.
Our work on image-match led me to suggest (what I think to be) an improvement in the way of storing and retrieving fingerprint documents.
For more information on how to join Deezer, have a look at our dedicated website:


