




co-authored by Hugo Sempere
Shows and conferences about the fast-evolving data technologies follow one after the other and yet each one is so unique! No year passes by without any new challenge to be discussed within the active and passionate data community that Deezer is proud to be part of. This year’s Data Works Summit didn’t disappoint, with subjects like the incoming GDPR, the necessity to keep a clear and clean data catalog, portability across an ever-growing number of languages and frameworks and speed improvements!
Some of our highlights were:
GDPR
The technologies empowering companies to handle data at scale have recently reached a new milestone. Indeed, the recent GDPR raises the bar in protecting and giving more control over personal data. Since our company only uses data to provide you with the best music streaming experience, and pay our distributors with a fair amount of royalties, there’s no reason we might have trouble applying GDPR’s guidelines.
Apache Ranger and Apache Atlas are two projects that help in achieving these data governance requirements. Apache Ranger is a tool that plugs on your Hadoop stack and provides you with a centralised security administration. It provides fine grained authorisation control user-and location-wise over your data lake. Apache Atlas is another Hadoop framework that also works closely with Ranger to better manage metadata across the data catalog. It basically helps in classifying, organising and making sense of the company data assets.
However, it still takes time when it comes to modifying legacy software to be compliant, as shows this interesting survey of the audience showing how prepared companies are for this change:

Enza Iannopollo and Bernard Marr both emphasized the opportunities that GDPR can bring to businesses which would, according to them, greatly outweigh its constraints. You can watch their keynotes here.
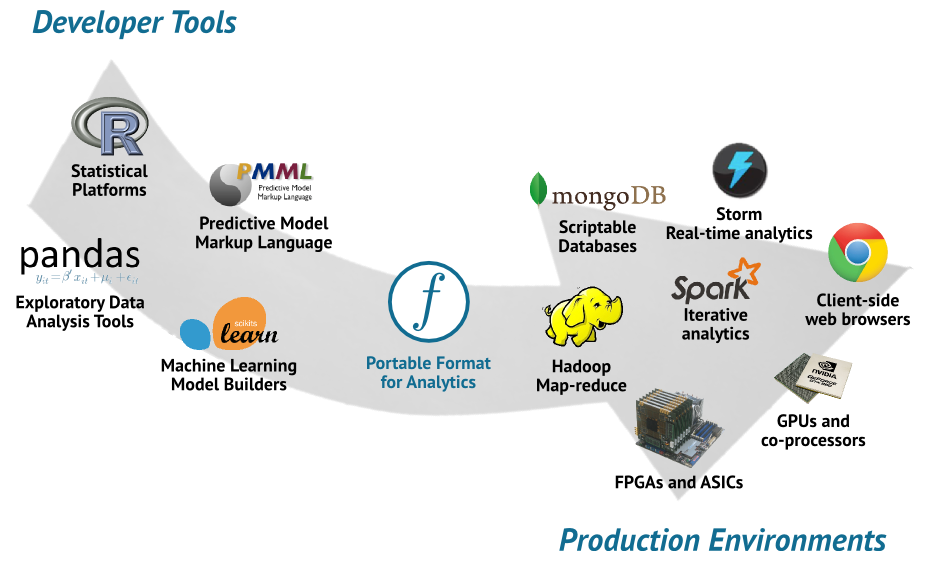
Portable format for analytics by Nick Pentreath
When it comes to developing Machine Learning algorithms and putting them in production at high scale, two states of mind fight against each other:
- A development phase requires flexibility, a good amount of trial-errors, and the ability to adapt quickly to feedbacks
- Algorithms put at high scale production requires a very rigorous and thorough upfront design and accepts no errors: this inevitably causes some rigidity after it is done
As our models may decay over time we might have to transition between the two states multiple times.
Nick introduced the Portable Format for Analytics (PFA) that aims at helping to “smooth the transition from development to production”. It provides a JSON description of any model that could be read by any language and any framework. Hence, it separates the production pipeline concerns from the model development, and removes environment constraints slowing down engineers in the process.
Spark 2.3 improvements by Yanbo Liang
The summit was also an opportunity for Apache committers to present the new features in Apache Spark 2.3.
Vectorized python UDFs, batch computation:
UDFs is a very useful feature of PySpark that enables user to have the flexibility of defining their custom operations. However, UDFs were previously computed one row by one row (for the Python interface of Spark), making it a slow process and preventing its use in the most challenging environments. Spark 2.3 introduces batch UDFs computation which greatly improves the performance of these operations!

More info here.
Image format in Dataframes/Dataset
Putting simple Machine Learning models in production in our data processing workflows is quite smooth thanks to the handy Spark ML library. However, working with more complicated models such as neural networks for image classification was still complicated due to the requirement of external libraries and the lack of Image simple representation in Spark. The latter is solved in the 2.3 version.
The related and interesting JIRA ticket can be found here.
For more info on Apache Spark 2.3’s new features, check out Databricks’ blog.
Apache Hadoop : Yarn improvements 2.8 to 3.1
Wangda Tan and Billie Rinaldi, Apache committers, gave an insightful view of Yarn majors improvements over the past year:
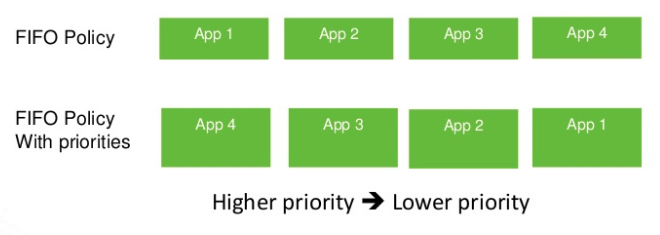
Application priority (2.8.X)
Default ordering policy is FIFO but now queue can have priorities among others:
Reservation (2.8.X)
Since 2.8.X a new system called ReservationSystem can reserve resources ahead of time, to ensure that certains critical jobs have enough resources to be launched. Check out hadoop documentation for more info.
Fast allocating containers (3.1.X)
A lot of work was made in Yarn to speed up containers allocation, and it can now allocate up to 3k containers per second.
GPU and FPGAs Support
Yarn can now use specific profile and handle GPUs and FPGAs resources.
More info on GPU support
More info on FGPA support
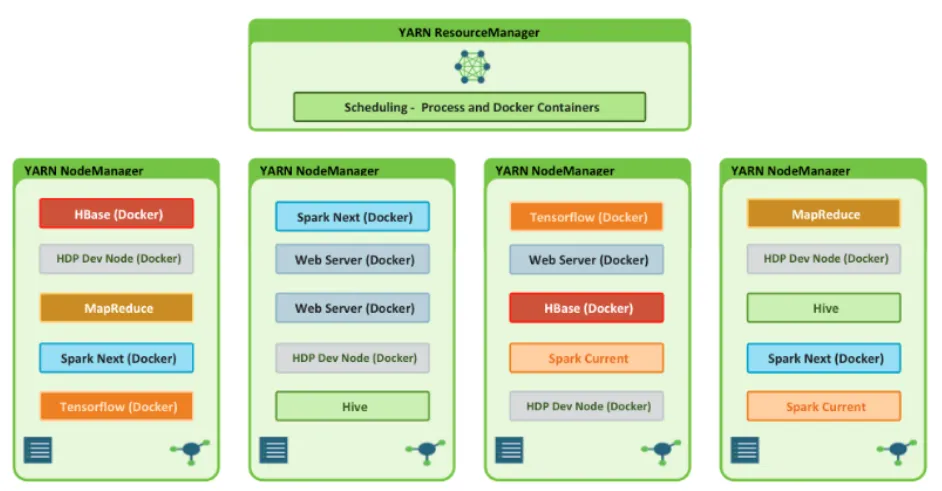
Containerized Applications (3.1)
From Hadoop 3.1, it is possible to run docker containers on YARN!
This new feature unleash a lot of new possibilities, such as deploying spark jobs with all needed libraries without installing anything on cluster or orchestrating stateless distributed applications.
Now back to work to put this brilliant stuff into practice… And looking forward to the next European edition!


