





Who are we?
We are the Data-Analytics team. Insights, numbers, dashboards… we provide data to our company. The goal? Help business and product teams in designing music and digital experiences that will be the best they can be for our users.
Why do we need to detect outliers?
As a tech data team, we rely on different KPIs. We check, provide, love and trust them. Why? Because the better they are, the happier our users are. In DATA we trust!
As a consequence, we want to detect any peak or drop, understand it and take actions!
How to detect them?
There are lots of ways to detect outliers on time series. Some are good, some are great!
We have used our own implementation of STL (Seasonal Decomposition of Time Series by Loess), which performs well. It decomposes a time series into trend and seasonality. The delta between reality and the fitted value is what we call the outlier score.
Tuning parameters in STL is critical. We have optimized them on a labeled dataset.
We use Tableau to visualize our results.
For example, the graph below represents streams in a certain country and on a certain device:

One of our main problems was the cost: it is a resource and time consuming process, so it cannot be applied to a huge number of cases.
But Deezer is a worldwide company available on a large number of platforms, and we want to explore all the cases, as every user counts! This is why we developed the What The Bug (WTB) project.
The scalable model
For a single KPI, we want to check more than tens of thousands of cases, so the model has to be as simple and scalable as possible.
Weekly seasonality
Like a lot of businesses, one of our main seasonalities is the weekly rhythm. For example, the graph below represents streams in a certain country, on a certain device and on a certain scale:

We clearly see the weekly seasonality, which implies high daily variations. So we have decided to look for the weekly ratio
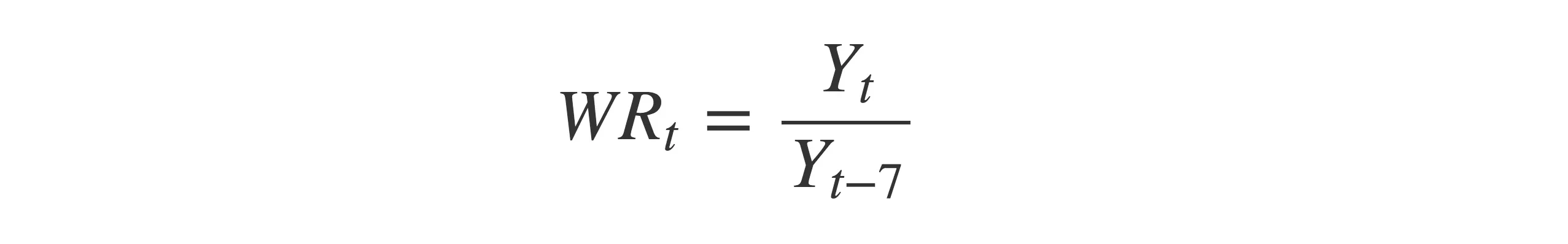

This transformation has another great advantage: it turns the time series stationary. Trust me, it makes it easier to detect outliers.
Now we have a set of values that we center and reduce (as good data scientists would).
It is tuned enough to apply one of the simplest outlier detector, i.e. a queue rule: after 2 (we could talk for hours of this threshold, this one works for us) standard deviations, it is considered suspicious.
Once it is done, we have to add a step to work on what matters: if there is a huge peak on streams in France in general, we do not want to check every sub-case such as IOS in France, Android in France, WindowsPhone in France, etc.
As a consequence, at this point we only return the suspicious cases that are not a sub-case of another suspicious case.
STL returns
Now we can apply our costly model, based on STL, to the limited subset of cases that have been pre-selected by the queue rule. Thanks to this model, we get numerical scores that rank outliers. Therefore we can prioritize and take actions on Ukrainian streams on tablet or downloads in South America! As the code is as dynamic as possible, we can easily add any metric we want!
To sum up WTB workflow:
- Apply a very simple and scalable model to detect suspicious time series
- Apply a complex and precise model to quantify anomalies
- Visualize on Tableau
- Take actions

That’s one way we play.
Of course, we do other things at Data-Analytics: we fight churn, we support Deezer partnerships, we look for trendy artists, etc. If you are interested, stay tuned!


