




co-authored by Huikan Xiang

At Deezer, we love to play different chords, and to play with different technologies. Here we will present a solution to the problem of receiving millions of messages per day from a REST endpoint, processing them and pushing them back to Kafka. Inspired by The Reactive Manifesto, we decided to use Akka, which perfectly follows the four principles of reactive systems: Responsive, Elastic, Resilient and Message-Driven.
From Customer Care To Big Data
Data-Core is the team responsible for handling the big data at Deezer and we collaborate closely with different teams to improve their processes related to data ingestion. One of the teams we work with wanted to improve the way we follow our communication and marketing campaigns.
At Deezer, we use a third-party emailing platform that helps us generate reports and statistics for the different campaigns. Once an email campaign is launched, each email goes through different statuses over the period: they can be delivered, opened or clicked among others. All these events are analyzed in real-time and batched by the CRM team.
The third-party emailing platform pushes the information of the campaigns to our REST API by sending a POST request with a JSON in the body. From our side, we handle, clean, process and store every message so that the CRM team can easily use them afterwards. While designing the API, we took into consideration that our application has to be always available and guarantee that no messages will be lost. Another aspect to consider is that the amount of API calls we will receive from our third-party is not constant. In fact it is highly variable per day and per second as shown in Fig. 1 and Fig. 2.


Considering these bursts of requests, the application should be able to handle those peaks without losing messages while keeping response times low.
Application Design
Based on all those requirements, we decided to implement the application using Akka to benefit from the HTTP module to create a high-performance REST API, the Actor module to make the pipeline of transformations and validations easier and the Persistence module to keep the state of the system in case of crashes and other systems’ downtimes.
Akka is a palindrome of the letters A and K as in Actor Kernel, from which it is inspired. The Actor model has been brought into Akka for its high efficiency and easy-to-duplicate characteristics. An Actor can be seen as a thread that is responsible for an atomic operation.
The Akka application is presented in blue in the Fig. 3.

The application is quite simple, we split the system in three actor roles. The first one is the Reception Actor that receives all HTTP POST requests and extracts the body. The second actor is the Kafka Producer Actor that receives messages from Reception Actor, constructs a valid Kafka record and sends it to Kafka. It also monitors the Kafka status. Finally, we defined a third actor that plays the role of a buffer in case Kafka is not available. The buffer is a persistent storage for disaster recovery (discussed later), which is an independent component to resume the system during failures and to achieve the zero-loss goal.
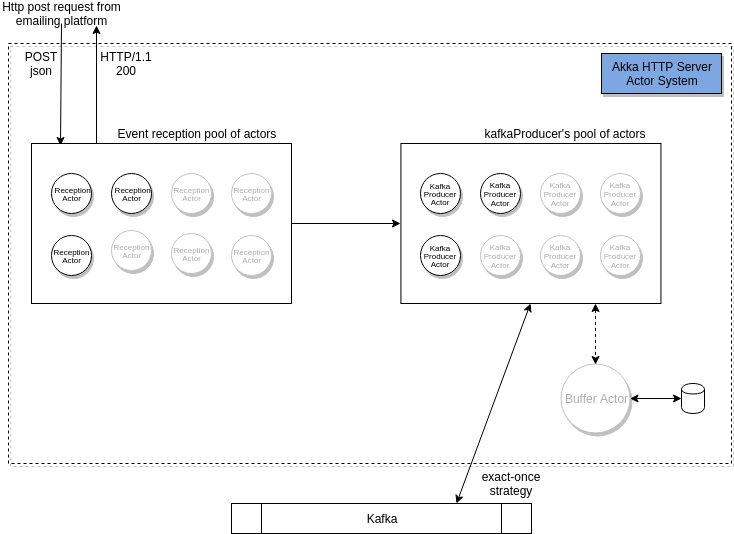
Each actor is defined as a “round robin” pool of actors that can be automatically resized depending on the load. If the amount of messages is low, actors are removed, and if the amount of messages is high, more actors are added so that the application is capable of handling bursts of messages. One of the characteristics of Akka is that each actor has a very small footprint. It can handle around 2 million actors per gigabyte of heap.
Resilience
One of the four principles in a reactive system is resilience and it means that when there is a failure, the system should stay responsive. In our circumstances, the system depends on two external components: the emailing platform and our Kafka cluster. Here we focus on discussing a potential Kafka cluster failure since it’s in the Deezer production scope.
In the system architecture diagram (Fig. 4), there is a Buffer Actor responsible for taking over the message ingestion in case Kafka is down. The dotted line between Buffer Actor and Kafka Producer Actor signifies its standby role.

The flowchart above (Fig. 5) illustrates how the Buffer Actor activates when the connection with Kafka is down (red X), and how the Kafka Producer Actor resumes after Kafka came back (black arrow). In this case, Record 1 is the ideal situation, in which we get an acknowledgement (with a Kafka offset metadata inside) back from Kafka after we successfully pushed a message.
In the unlikely event of a failure in our Kafka cluster, we might have a fatal error or just no reply until a timeout is reached. This is depicted with Record 2, which is forwarded to the Buffer Actor whose job is to persist the Record for a limited time using its own persistence layer. Every message that failed to be transmitted to Kafka is stored in this buffer. As soon as the downtime is over, all new messages will be transmitted in the same manner as Record 1. In regular time intervals, the Kafka Producer Actor will ask the Buffer Actor if there is any message in the buffer. If there is any, the Kafka Producer Actor will retrieve them and try to send them again to Kafka.
Deployment
Deploying an Akka Application is dead easy. After getting some pieces of advice from our friends from the Infra Team, we decided to work with a Docker container and deploy the application in our Kubernetes cluster.
In our project, we use SBT as the build tool, which has a plugin called SBT Native Packager. This plugin offers a very simple way to build an Akka application in many formats and in particular simplifies the creation of a docker image. This comes as a very handy tool since it configures the Akka HTTP server as an entry point listening on the chosen port.
The current pipeline is easy: we push our code to our repository, our Jenkins service builds the docker image and it is automatically deployed in our K8s cluster ensuring high availability.
Performance
For our requirements, we allocated 1 container with 512 MB of RAM and 2 CPUs. We tested our application in a development environment, which is limited in network bandwidth but sufficient to verify the throughput and behavior of the application.
To test our Application we use Apache JMeter to simulate many HTTP requests. When the application is idle (ie. no requests but waiting for connections), the CPU consumption is around 0.001–0.002 and the memory consumption is flat at 129 MB. With our simple configuration, we achieved a throughput of ~10,000 messages per second (Fig. 6) with a very low error rate of ~0.5%.
An interesting point is that it is possible to see some spikes in the CPU usage in the ‘CPU Consumption over time’ graph. This is because we allowed our container to have short bursts in our Kubernetes cluster configuration. We also tried a different cluster configuration: we added two containers to test high availability and we had a linear increase in the throughput (20,000 messages per second).
Based on our results, being able to handle 10,000 messages per second with one container of 512 MB of RAM and 2 CPUs is vastly enough for now.

What’s Next
Akka is fun to code, so fun that we are already planning to replace another piece of our stack: a module that consumes logs from Kafka and ingests them directly to HDFS. Stay tuned!


