Deezer @ Kaggle Days Paris — 5 Takeaways from the Presentations and the Competition


I was lucky enough to attend the second edition of Kaggle Days, which took place in Paris in January. 200 Data Scientists from all over the world gathered over two days for exciting Data Science-oriented conferences, workshops, brainstorming sessions… and an offline Kaggle competition!
If you haven’t heard of Kaggle, it is a famous online platform dedicated to Data Science projects. In my opinion, it is the perfect space to learn and keep yourself up to date with the latest Data Science trends, so I was expecting quite a lot from this event. I will spare you the suspense and say that I wasn’t disappointed! Below are a few takeaways from the event that particularly inspired me.
Day 1 — Learning by sharing
The Kaggle Days have quite a unique format: along with traditional presentations, there were also some workshops and even brainstorming sessions on business problems. The event facilitated all sorts of discussions, and sharing knowledge is the organizers’ primary concern.
Another noticeable particularity is that speakers were not representing a specific company, they came as passionate individuals. And I have to say I was amazed by the quality of the presentations! Their content was tailored to an audience of Data Scientists aspiring to be better at what they do, whether they do it for an industry day job or a competition.
Here are some quick but insightful ideas I discovered:
Interpretability of Models

During his presentation, Alberto Danese explained that many companies that are not technology-focused still struggle to make Machine Learning go from a POC to production. According to him, the major obstacle in that regard is the usual lack of interpretability of the models that work best. Indeed, since we are still unable to see in N-dimensions, we need proper tools to ‘proxy’ the understanding of our model’s intrinsic mechanics.
Most of us know that we can globally measure features importance of our models quite easily. But are you aware of LIME and/or Shapley concepts? They provide a framework to understand any model predictions locally!
LIME approximates the behavior of the model around the local prediction by a linear model, which we can easily interpret. A good starting point to learn more on this is this Youtube video made by the LIME paper authors.
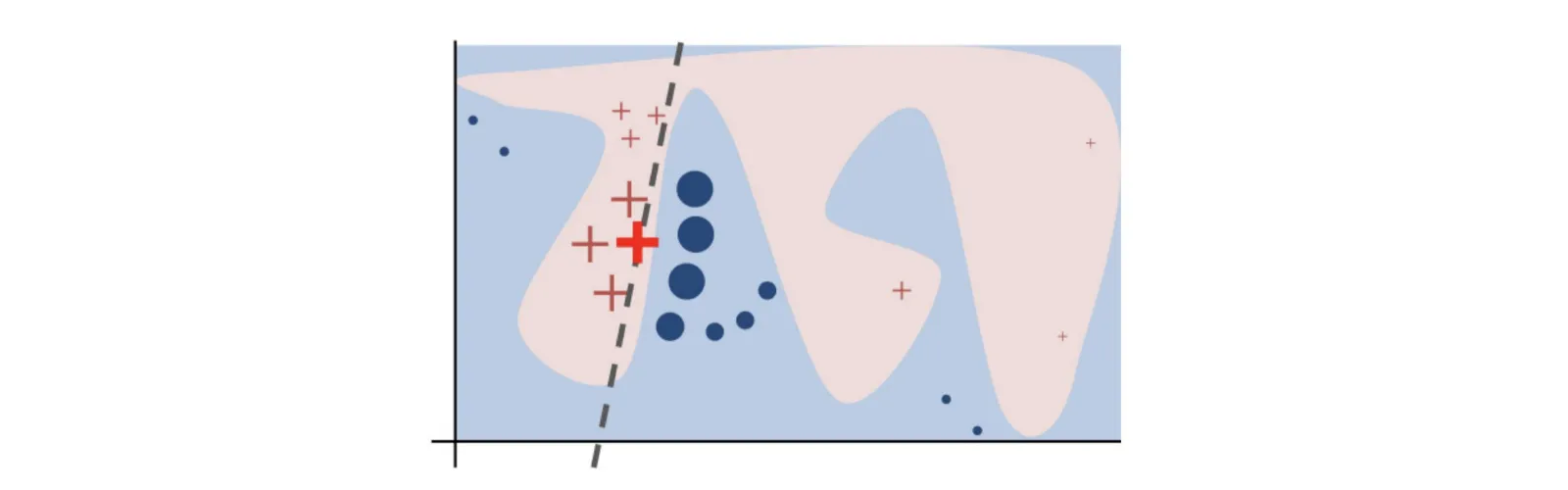
On the other hand, Shapley’s additional explanations use game theory to explain predictions. My naive understanding is that it looks at how much each feature contributes to the final result, one after the other, in a specific order. Then, it repeats the same process for all possible orders and averages the contributions out. Have a look at the github repository to learn more about the concept.

Isotonic Regression
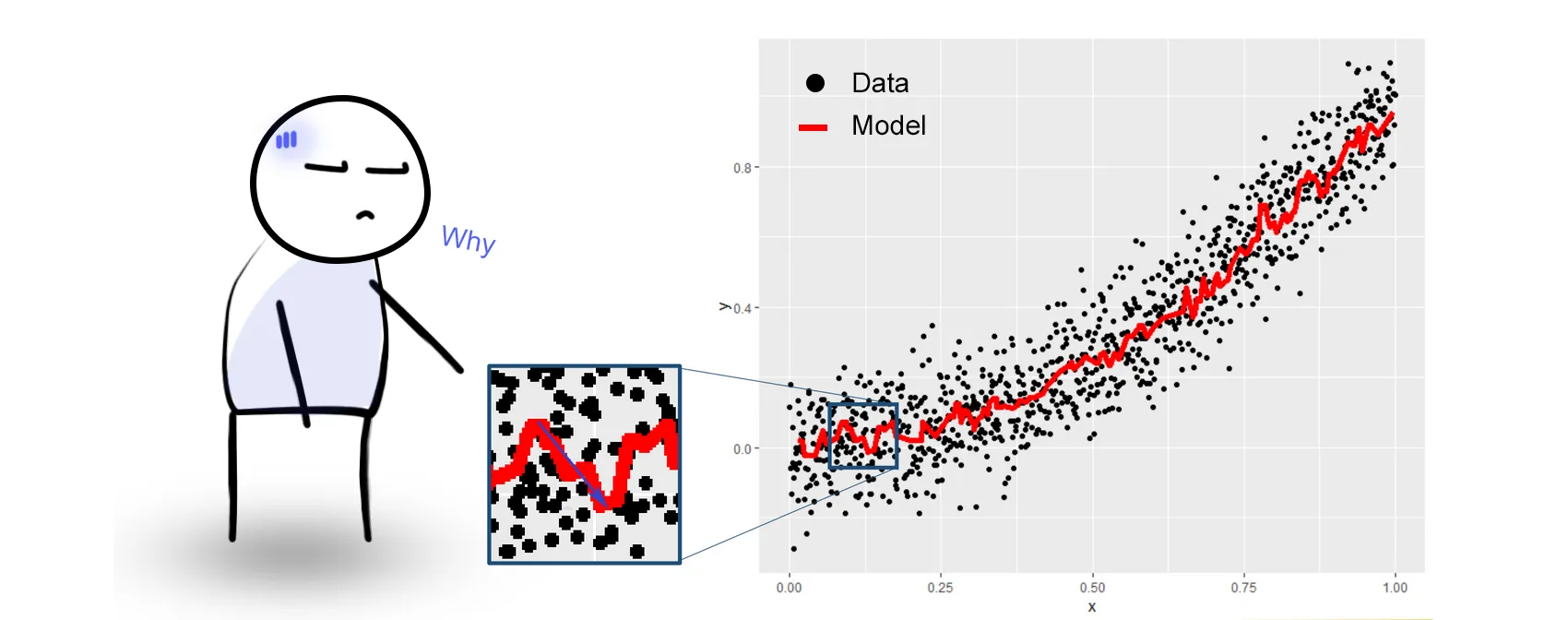
In case you have an obvious monotonicity constraint between a feature and your target variable (let’s say square meters area of a house, and it’s price), you can constrain your model to force him to follow that constraint (here price = f(area) should be increasing only).
It seems straightforward but I’ll be honest: I just hadn’t thought about this before. Thanks Alberto Danese and Stanislas Semenov for the trick! As you can see below, it greatly improves the look of the model, even on simple problems, and probably prevents some overfitting issues.

Making models more intuitive and better interpreting them are two challenging aspects of Data Science, and these few insights will definitely help me on my day-to-day job. What is knowledge without a little bit of practice though?
Day 2 — Learning by doing
On the second day, we took part in an 11-hour offline Kaggle competition: perfect to get a hands-on experience on challenging tasks! The objective was to predict the sales of ~2000 LVMH products (LVMH being a sponsor of the event) 3 months after their release. Quite an interesting task with a lot of different data sources to train our models on (e-commerce navigation metrics, physical sales on the first few days following the launch, descriptions and pictures of the product, etc.)!
Here are the three key things I will most remember from this competition:
1) Practice makes (your code library) perfect!
We all know that practice makes perfect right? In addition to improving your overall knowledge and coding skills, it also helps you build your own library of code snippets that you will be able to instantly reuse in the future. Of course all competitions are different but there are always some functions you used previously that could make you good here, and very quickly! So keep practising! Competitions such as these make awesome practice material due to a wide variety of problems which you might not encounter in your day job.
2) When validation doesn’t work…
Your training and validation score match, however your testing score is worse! What could possibly happen here?
Many things actually. For example, if your training/validation split does not match the real initial training/test split, it will prevent you from predicting your model performance accurately. An accidental shuffle might also distort your predictions. Eventually, some features’ distributions might totally differ from training to testing set, and it sometimes happens for obvious reasons if you think intuitively about the underlying business problem and the way data was split.

Your Cross validation splitting technique should mimic the training testing strategy to ensure predictable performance: this may deserve a prior good thought. For example, testing a model that predicts people’s clothing choices with today’s data will likely yield very bad results if the model was trained and validated with data from the 80s…
3) Beware of toxic features!
I am highlighting this because at first we blindly threw all the features in the model, expected good results and were surprised by the very low testing score. The best way to do it was to start with a small number of features and then add features incrementally!
Of course, we usually have more time to test these different combinations of features in our day job. But these time constrained challenges force us to use a clean protocol in order to be efficient, which should definitely be part of our best practices if we are to improve our daily work.
In the end, our team placed 21st out of 77 teams: a good score but also with room for improvement! Thank you to my great teammates Clément Dessole and Tuan-Phuc Phan, Kaggle Days’ staff for the organization and Deezer for supporting these kinds of initiatives. These two days were both informative and fun, and gave me the opportunity to get better at what I love and do for a living, while meeting inspiring people from the same community, who share my interest. That’s what I like about these events and why I encourage you to seize these opportunities whenever they present themselves. So…see you next time?
Credits
Alberto Danese — KaggleDays 2019 Paris presentation: “Machine Learning Interpretability: The key to ML adoption in the enterprise”
Stanislav Semenov — KaggleDays 2019 Paris presentation: “Tips and tricks for Machine Learning”