


Confidence-Based Weighted Loss for Multi-label Classification with Missing Labels

The problem of multi-label classification with missing labels (MLML) is a common challenge that is prevalent in several domains, e.g. image annotation and auto-tagging. In multi-label classification, each instance may belong to multiple class labels simultaneously. Due to the nature of the dataset collection and labelling procedure, it is common to have incomplete annotations in the dataset, i.e. not all samples are labelled with all the corresponding labels. However, the incomplete data labelling hinders the training of classification models.
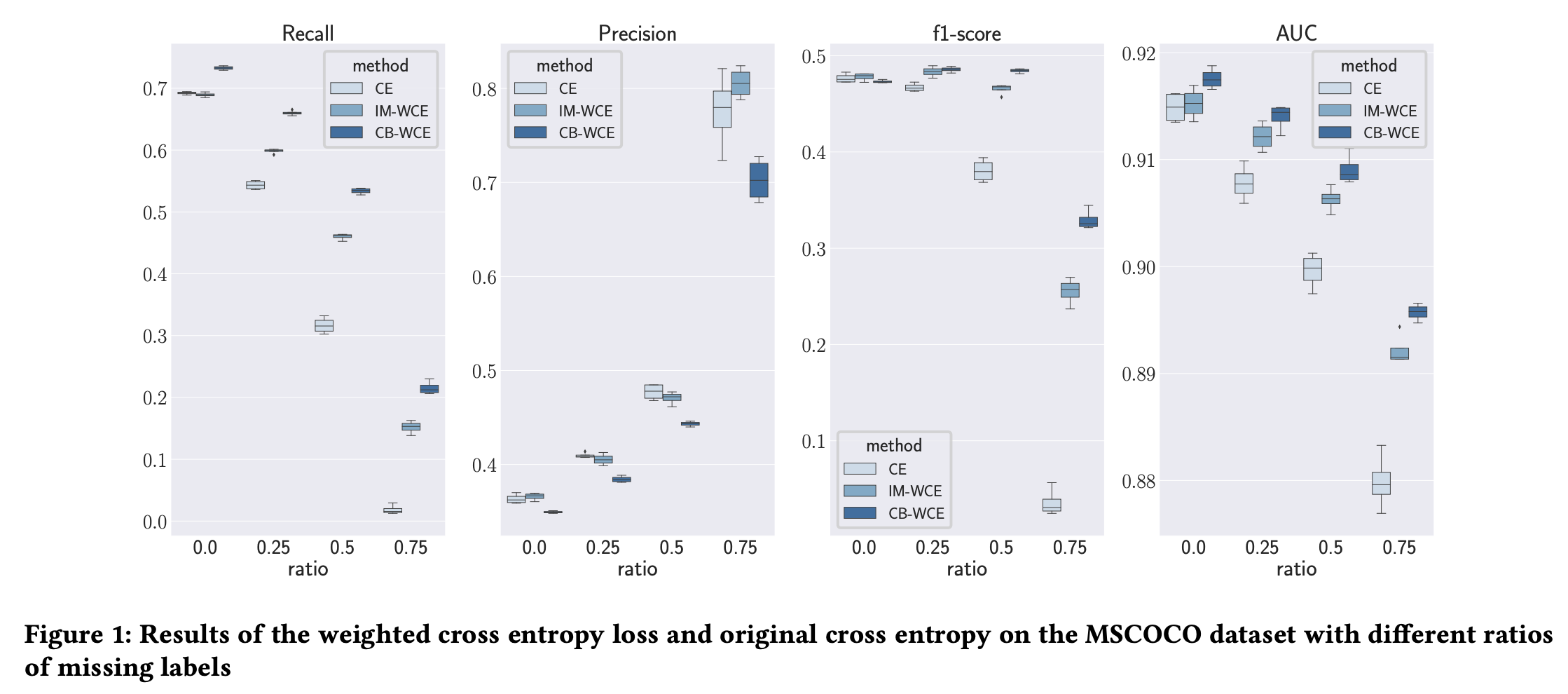
MLML has received much attention from the research community. However, in cases where a pre-trained model is fine-tuned on an MLML dataset, there has been no straightforward approach to tackle the missing labels, specifically when there is no information about which are the missing ones. In this paper, we propose a weighted loss function to account for the confidence in each label/sample pair that can easily be incorporated to fine-tune a pre-trained model on an incomplete dataset. Our experiment results show that using the proposed loss function improves the performance of the model as the ratio of missing labels increases.
This paper has been published in the proceedings of the Annual ACM International Conference on Multimedia Retrieval (ICMR 2020).


