





When meeting someone new, first impressions are crucial: the expression “You never get a second chance to make a first impression” indicates how people often make snap judgments. The same holds true when installing and trying a new application for the first time. Just as you’d negatively judge someone showing up late to a first date, what would you think of an application that gives you far off the mark recommendations, even though you explicitly stated your preferences?
In this context, online music streaming services must quickly come up with accurate content that new subscribers are likely to enjoy. However, while we know recommendation algorithms work well for users who have had enough interactions with the service (and that their preferences are well known), recommending music to new users remains a largely unresolved challenge for the research community. In scientific literature, this is commonly referred to as the user cold start problem.
In order to match every new subscriber with Deezer, the Recommendation and Research teams have worked together to improve music suggestions specifically for these new users. In this post, we describe the system we recently deployed at Deezer to address this issue.
Some context

A brief overview of recommendation techniques
Broadly speaking, recommendation systems can use two types of strategies (or combinations thereof) to find relevant content for users:
- The content-based approach aims at creating user and item profiles that characterize their nature. For example, a song profile can include its music genre, mood, date of release, artist(s), popularity, etc.; a user profile can be described by their age, country of registration, favorite music genres, etc. However, this strategy requires gathering external information that might not be available, reliable or easy to collect.
- An alternative to this strategy is to rather rely on past user behavior without requiring the creation of user or item profiles. This is known as the collaborative filtering approach. It analyzes relationships between users and interdependencies among products to identify new user-item associations. In a few words, the preferences of one user within a set of items are predicted by leveraging the known preferences of a set of similar users.
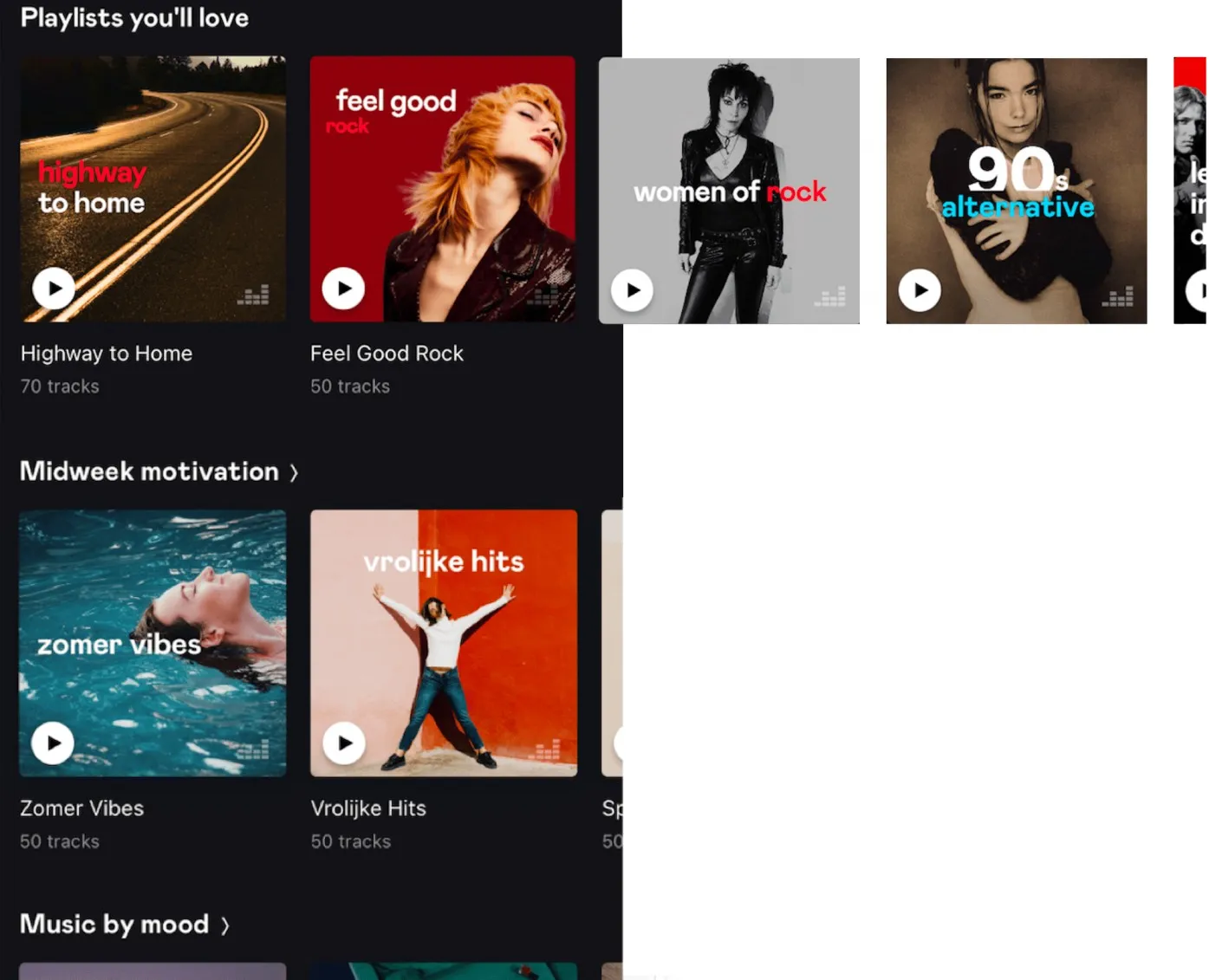
In recent industrial-level work, latent models for collaborative filtering proved to be efficient. In a nutshell, they consist of learning a vector space representation of users and items (i.e. a compressed way to represent users), which we call embeddings. In this context, proximity should reflect user preferences, typically via the factorization of a user-item interaction matrix. Such user preference representations are very convenient in a production environment. At Deezer, we use them to populate the playlist recommendation carousel for instance, which is a swipeable list of playlists on the homepage, as illustrated below.
The problems
Yet, in the real world of music recommendations, we are facing three issues with these latent models:
- First, latent models are trained only once a week in our stack. How can we recommend playlists in the above aforementioned carousel if we do not have any embeddings available for the users who have registered right after the training? We cannot afford to wait several days for the next model to be trained to recommend content to these new users.
- Second, what will users think of Deezer if we simply recommend the charts to them (which is common in industry to deal with fallbacks) when they open the app for the very first time after registering? We need to be able to recommend as much personalized content as possible, as early as the registration day. So our predictions must be performed in real time, taking into account the actions of our new users within the application.
- And third, it may happen that we compute low-quality embeddings for existing users who have not interacted much with the platform. We wish to improve music recommendations for these users too by also computing a refined embedding that takes any available information into account, just like for new users.
In light of this practical industrial point of view, we need to tackle this cold start issue. More formally: how can we incorporate new users into an existing latent space model based on already registered users data?
Implementing our solution
What data should we use to project new users in the embedding space?
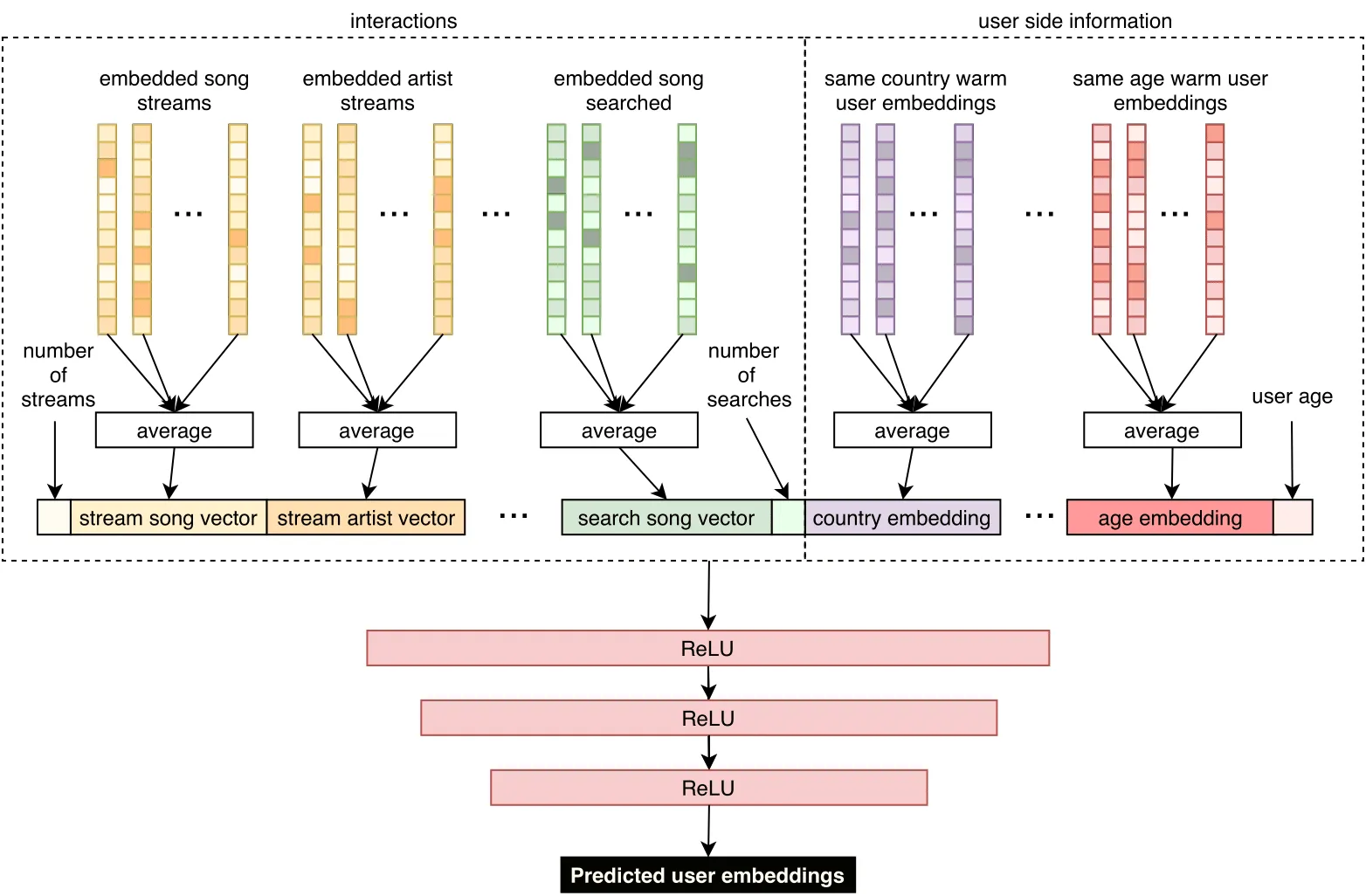
To predict new user embeddings, reflecting what kind of music these users will like, we propose to train a machine learning model specifically dedicated to this task. We gather users that are now senior and active enough in our database; in contrast to the cold users, referred to as warm users here. We retrieve the information as if it was their registration day, ignoring all their subsequent interactions. That is to say, we simulate the cold start situation for warm users — who are actually well represented with an embedding. We use diverse information such as country and age, as well as interactions (if any), both positive or negative, like streams, additions to favorites, bans or dislikes, searches, etc. We enrich these features using the warm embeddings of users and items — they can be tracks, artists, albums or playlists. For each type of interaction and music entity, embedding vectors are averaged, as illustrated in the following figure. We obtain fixed-size representations for both demographics and interactions, meaning they are independent of the number of modalities or interactions, which is crucial for scalability in a production environment.
How do we predict user embeddings in this context?
As described in the previous figure, we then propose a three-hidden layers neural network aiming at predicting user embeddings. We train the model on warm users by iteratively minimizing the mean squared error between the predicted user embeddings and their actual value by stochastic gradient descent. Once we obtain a fully trained model, one could directly provide fully personalized music recommendations from this predicted user embedding by retrieving the most similar tracks for each user via an exact or approximate nearest neighbor search.
Given a prediction, how do we recommend music?
As we empirically show in our experiments (see the paper for full detail), leveraging similarity directly on the predicted user embedding can still lead to noisy results for users with very little to no usage data. As a consequence, in production, our system adopts a semi-personalized recommendation strategy instead, as described in the following figure:
- Warm users are clustered using k-means on their embeddings to form homogeneous groups of music tastes.
- New user preferences are predicted by projecting them in the same embedding space as previously described.
- Each cold user is assigned to the warm cluster whose centroid is the closest to its predicted embedding vector.
- We recommend the pre-computed, most popular tracks among warm users from the assigned cluster.
This approach is all the more relevant in our industrial stack at Deezer as we can adapt the type of recommended content for new users here. Indeed, we can better recommend music items such as tracks, artists, albums, but also some of the personalized cards present in the carousel of our homepage such as the new release or the discovery card.

Challenging the quality of our solution
How did we validate our approach before A/B testing it?
For offline experiments (experiments prior to A/B testing), we extracted a dataset of fully anonymized Deezer users, composed of 70,000 warm users for the training dataset, and 30,000 cold users for the testing and validation ones. We gathered socio-demographic and interaction information available by the end of registration day. We compared the performances of our approach with two selected models from the state of the art, DropoutNet and MeLU, by measuring their ability to predict the future streams of new users, i.e. after registration day. Our semi-personalized approach performed significantly better on the standard ranking metrics for recommendation we considered: standard recall (i.e. the fraction of relevant tracks that were retrieved), precision (i.e. the fraction of relevant tracks among the retrieved ones), ndcg (i.e. the Normalized Discounted Cumulative Gain, which is a measure of ranking quality that takes into account the order of the retrieved tracks).
How did we A/B test it?
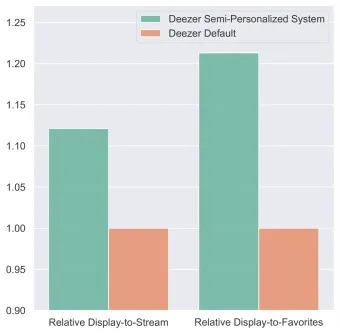
We launched a large-scale A/B test to assess the ability to recommend personalized playlists in the carousel of the Deezer homepage that we mentioned at the beginning of this post. In the following figure, we can observe that our new semi-personalized system led to significant improvements of the relative display-to-stream and display-to-favorite rates. The display-to-stream rate refers to the proportion of users who streamed when the playlists were displayed on their homepage: in the graph below, we see that our strategy outperformed the previous approach in production by more than 10 percentage points. The display-to-favorite rate refers to the proportion of users who added the playlists displayed to their favorites: here our strategy outperformed the previous approach by more than 20 percentage points. Such results validate the relevance of our proposed system, and emphasize its practical impact on Deezer 🎉.
What’s next?
Our offline and online evaluations show that we managed to improve recommendations for new users whose embeddings were lacking in our production stack. Nevertheless, here we solely focused on improving our very first recommendations with all the information available on Deezer for brand new users, and not the reaction (positive or negative) to these recommendations, which begs the question, why not take this better into account to improve user representations? In the future, we would like to include temporal aspects in our approach, and fine-tune our recommendations. We have also thought about more sophisticated approaches at different stages of our system, such as proposing graph methods for user clustering, which show promising results in the scientific literature. To be continued!
For further information, please refer to our paper:
A Semi-Personalized System for User Cold Start Recommendation on Music Streaming Apps Léa Briand, Guillaume Salha-Galvan, Walid Bendada, Mathieu Morlon and Viet-Anh Tran. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2021), 2601-2609.
If you would like to help us improve the Deezer experience for millions of users, check our open positions and join one of our teams!


