



co-authored by Denis GERMAIN

Why would you do that?
At Deezer, the majority of our infrastructure is hosted on site and it fits most of our needs.
But maintaining a world-class music streaming platform can be challenging at times. The services offered by cloud providers sometimes deliver more value than what we as the SRE team can bring to our users — the Dev teams.
To manage these types of services in a DevOps way, one Infrastructure as Code (IaC) tool stands out: Hashicorp’s Terraform.
Terraform is an open-source infrastructure as code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. Terraform codifies cloud APIs into declarative configuration files.
– Terraform website
What we really like about Terraform is that it allows us to build a repeatable infrastructure with just a few lines of HCL files (Hashicorp’s domain-specific language). The actual state of the infrastructure is stored either in a local file or in a remote storage system, and only diffs are applied when and where modifications are made. Last but not least, the adoption of this tool is wide, which helps us add new services reliably and onboard dev teams.
To the day, our Terraform repository has:
- Over 900 Terraform “.tf” files, more than 35,000 lines
- ~4,000 commits, 1,400 pull requests
- ~40 contributors from many different teams (and rising rapidly)
Terraform’s limits
When you only have a few objects in Terraform, everything is fine.
But when you start having hundreds of files (like we do), it becomes tedious to work simultaneously on the same Terraform code. The file that stores the state of the infrastructure has to be up to date and synchronized among all contributors.
It causes locking issues and time consuming diffs computation, making the Terraform at scale experience “not so great”.
There are multiple strategies to work around this, but we found no solution to all our problems.
You could separate individual projects or teams in different directories and have Terraform states for each. That way, every team could work independently on their own infrastructure. But the Terraform code tends to become duplicated between similar projects from various teams — even if you use “Terraform modules”, as we will see later.
From experience, duplicated code often leads to human error and we try to avoid it as much as possible.
You could also create one big monorepo where you would store all your Terraform projects in different directories (each with its individual state). You could then use the “Terraform module” feature to factorize HCL code in those sub-directories — either in this monorepo or in separate distant repositories.
But even then, you would still have to duplicate some variables like the billing account for your cloud provider for example, or some standard values you use nearly every time.
Enter Terragrunt!
To help work around some of the limitations of Terraform, Gruntwork released a tool called Terragrunt, which is — to put it simply — a Terraform wrapper.
You may already know Gruntwork for its various cloud native and Terraform oriented repositories like “Terratest” (which allows you to test your Terraform code), the “AWS Infrastructure as Code Library”, Gruntwork Landing Zone for AWS, etc.
The main idea behind Terragrunt is to give you the tools necessary to achieve DRY code (Don’t Repeat Yourself), aiming at reducing repetition.
In this post, we will walk you through the main features and advantages of Terragrunt, and show you how it will save you from writing the same variables 358 times!
Note: This post will show you how we use Terragrunt at Deezer. It may differ from Gruntwork’s own example.
Prepare
The very first thing to do if you want to try out Terragrunt is of course to download it 😉 Terragrunt’s source code is available here and pre-built binaries are available here.
To get a good idea of the features that Terragrunt unlocks, we are going to use a demo environment featuring a directory hierarchy like this one:
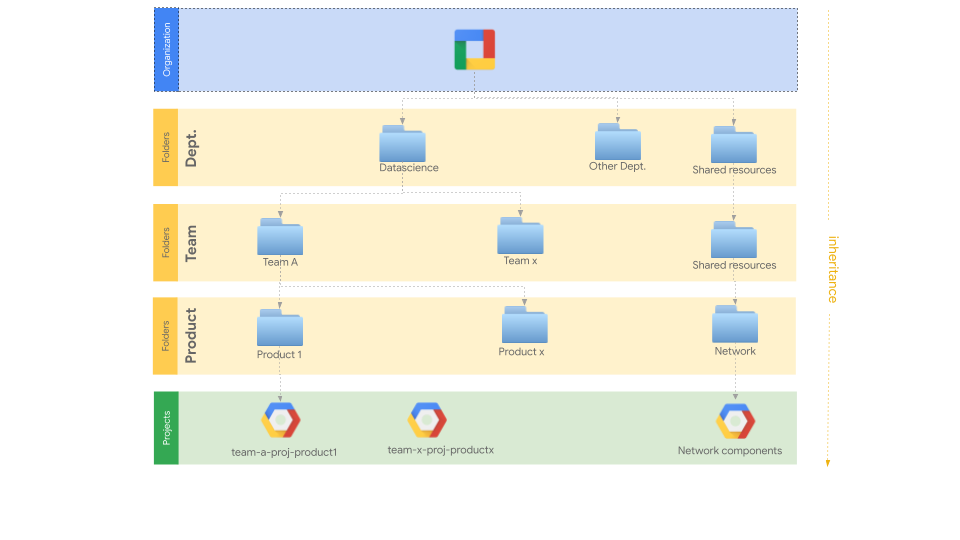
Note: We chose Google Cloud Platform as a provider for this example, but Terragrunt can work in various contexts and with all the other Terraform providers.
We are going to use this git repository, containing plain Terraform code, as a starting point and we are going to DRY it, step by step:
https://github.com/deezer/terragrunt-example/
For readability reasons, we will only describe the actions and explain each step. But you can also navigate through the various commits to see the “diff” from each section of this tutorial.
Let’s factor the variables
Dealing with many cloud projects means dealing with a lot of variables. Many of those variables would be exactly the same but copying them is an error prone process: Terraform users would forget to change what needs to be changed and we all know that duplicating code (or variables) is not a good way of doing things.
This led us to look for a solution to factor the variables, and we knew that we were not the only users facing this issue. We were looking for a system that would permit variable inheritance through folders and we found the exact match with Terragrunt.
The following before/after screenshot shows what we achieved with Terragrunt on the projects’ variables. We found a way to factorize the values, on different directory levels, and we’re going to show you how! 😉
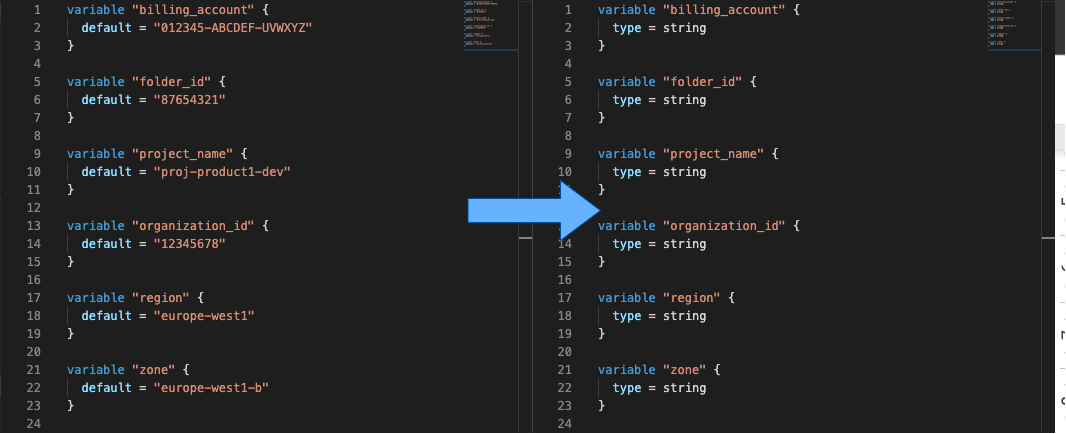
A configuration file
First of all, we need to define Terragrunt’s configuration in a file named terragrunt.hcl. This file is written in the same syntax as Terraform and uses a set of builtin functions to achieve what we want. For more details, take a look at the official Terragrunt documentation.
For our use case, we need to have a terragrunt.hcl file at two levels of this repository:
- At the project level, where .tf files are located, to be able to run Terragrunt commands in it. We will call it the local configuration.
- At the root of the repository to share this configuration across all the other folders. We will call it the global configuration.
The repository will then have the following structure:

At the project level, we use an include block followed by the find_in_parent_folders() function. This function searches the directory tree upward from the current terragrunt.hcl file. It returns the absolute path to the terragrunt.hcl file that is located at the root directory, which contains the global configuration.
This include block will then retrieve the declared configuration at this path and apply it to our project.
Projects won’t contain any specific configuration, all is based on the global configuration. It ensures that we have a unique configuration in this repository, ruled by one file.
Global variables
Let’s say we want to share a set of variables with all the projects, for instance the billing account ID that is shared with all the projects of our scope. To do so, we will simply use inputs in the global configuration:
Inputs aim to replace the empty declared variables in projects, usually located in a variables.tf file, as follows. Once you declare an empty variable and its type, it will be filled with the inputs provided above.
So this is a way to spread variables from one file to all projects. But what if we want to share a variable that is only in the scope of a particular folder and not the entire repository?
Folder scope variables
Unlike built-in functions that can only be used in Terragrunt configuration files, inputs can be set in other .hcl files. That way, we can put these files wherever we want in the repository to make all subfolders, and thus projects, inherit those inputs values. To do so, we use the read_terragrunt_config function in the global configuration for every .hcl file we wish to include, and merge those inputs together.
So, if we have variables that are specific to a folder, like the team’s tech leader and their contact for example, we can have a file named team.hcl at the root of that folder.
For team-a, it would be at this path: dept-datascience/team-a/team.hcl, with the following values.
And team-b: dept-datascience/team-b/team.hcl.
As a result, we will obtain different maps of values, depending on where your project is located.

Project variables
Factorizing variables is not suitable for all projects as there can still be exceptions — like if we wish to use a different region than the default one. If you need to override a variable that is declared in an upper level, you can simply use inputs in your local configuration using the name of this variable.
Going further
As SREs, we always seek for more automated processes. Thanks to Terragrunt’s functions, we figured out a way to automate GCP projects’ naming. We decided that every GCP project ID and name should be defined by the directory name that contains the project definition and its resources. For example, if the folder that contains the “.tf” files is named “project-A”, the project will be named accordingly in GCP.
It can be done by using the following code as the project name variable:
That way, you will never wonder which GCP project this directory is used for. The name will speak for itself.
Let’s continue with the backend configuration
At Deezer, we use a remote backend to store our Terraform projects’ states — a GCS (Google Cloud Storage) backend to be more precise. Every project’s state is stored at a different path, and sometimes in a different GCS bucket. But this path will always contain the project’s name and the bucket could be dedicated to a team, so obviously there is a way to automate things.
When you first try to use variables with backends, like everywhere else, you face this issue: a backend block cannot refer to named values (like input variables, locals, or data source attributes).
Fortunately, Terragrunt offers the possibility to use variables in a remote_state block. We decided that the buckets would be defined in “backend.hcl” files, shared by a few directories. For example, all the projects under team-a would use the “tfstate-teamA” bucket.
Regarding the prefix, it is defined with the path_relative_to_include() function that returns the path from the root of the repository to the project. The path for project team-a-proj-product1 would be ”dept-datascience/team-a/product1/team-a-proj-product1”. This way, we will always have a unique path to your state.
We first showed you that our folders’ naming can matter to define our cloud resources with the projects’ names. So can the structure of the repository.
In your local configuration, you will need the following snippet. The backend configuration will be filled by Terragrunt so you won’t ever have to copy-paste those backend files like you used to.
One command to rule them all
One feature that we didn’t know we needed until we discovered it is the run-all command.
run-all is a Terragrunt CLI option that enables you to run a command recursively on all the subfolders that contain a terragrunt.hcl configuration file.
For example, if you changed one of the global variables and want to apply this change to all projects, you will simply run the following command:
$ terragrunt run-all apply
You can use this command on a daily basis, when developing your local environment on something that could impact other projects. Or you can also take advantage of it in your CICD pipeline and make sure your infrastructure is always up to date with the repository.
Conclusion
As you can see, Terragrunt really helps a lot when you work with Terraform at scale.
If you carefully consider the hierarchy of your Terraform git repository, variables that apply to most projects can be either deduced from the directory tree or from cleverly placed upstream .hcl files.
While using Terragrunt adds a little complexity, it also unlocks useful functions to make your code even more factored.
This all leads to cleaner code, better maintainability and less code duplication.
We probably wouldn’t advise you to use it if you just started with Terraform, as it adds overhead for little gain at first. But if you are getting close to the number of lines, files, or contributors we have at Deezer, then you should definitely check it out!
Do you wish to learn and share with our community of developers, and contribute to making the Deezer experience a better one? Check our open positions!


