





Many years ago, Deezer signed its first contract to obtain a small catalog of podcasts, a few thousand only.
A system was developed to efficiently import and update them on a regular basis:
- podcasts import days were based on the publication dates of their previous episodes over a specified time frame
- depending on their importance they were imported on different schedules ranging from once every 5 minutes to once a day
However with time, Deezer has signed contracts with major podcast distribution platforms and opened podcast submission to independent podcasters as well.
The podcast catalog has grown more than tenfold — actually doubling every year — with the total number of episodes reaching dozens of millions. With that came the problem of scalability.
The problem
With so many podcasts to update on a regular basis, two issues appeared:
- podcasts were no longer imported on time
- bandwidth was heavily wasted considering the massive amount of pulling done for nothing
Simply increasing the number of workers would only buy us some time but would in no way be a viable option in the long run.
It would consume too many resources and upgrading our machines was not an option due to the hardware shortage at the time and the estimated cost. Besides, it would also obviously increase bandwidth waste even more.
In order to tackle these problems, we devised a 3-step plan.
The biggest issue lay in our mechanism of pull, which tried to blindly import every podcast just in case something had been updated.
Unfortunately, relying on HTTP headers such as Last-Modified wouldn’t do the job because of their lack of reliability in many hosting servers.
Step 1: Distributors push API
Since we already had a submission API for our partners, we offered one of them (Ausha) to push updates directly on our API, and they were thrilled to give it a try.
Given that more than half of our podcast catalog is hosted by partner distributors, if all of them were to join the effort, we would reduce the load on our pull import by more than 50%.
The architecture here is really simple:
- the distributor sends a POST request with the podcast topic (usually the podcast url) to update
- our backend retrieves the podcast
- a message is produced
- the message is consumed by the podcast importer
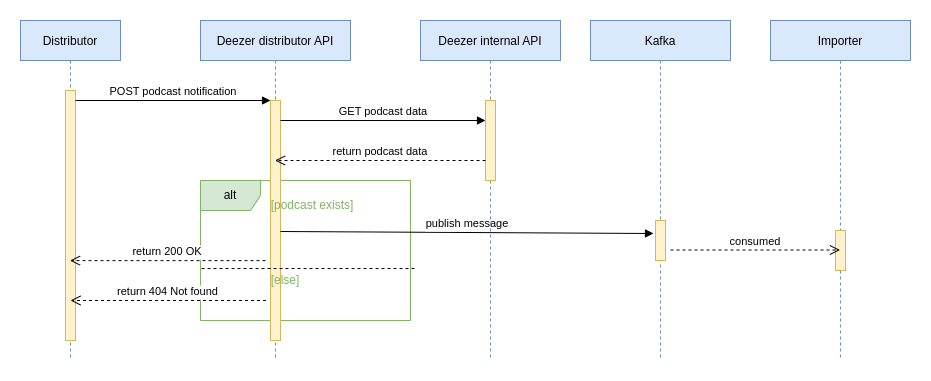
This solution was quick to develop and worked just as expected: podcasts are now updated mere seconds after being published on Ausha.
Since the first implementation, we have offered the solution to other partners, and so far, thousands of podcasts have become managed by this push API.
On top of the import speed benefits, Ausha assessed the environmental impact of the bandwidth reduction by analyzing the decrease in RSS downloads. We published a joint blog post about it.
Step 2: the Websub protocol
If you’re familiar with the ecosystem of podcasts, chances are you may have heard of Websub, and wondered why we bothered developing an API for distributors instead of just using Websub.
There are a few reasons for that, namely:
- not all distribution platforms use Websub
- the theoretical impact of Websub is lower than the distributors API, with roughly 40% of our podcast catalog being eligible
- the required development is also bigger
Here is a simplified schema of how Websub actually works:
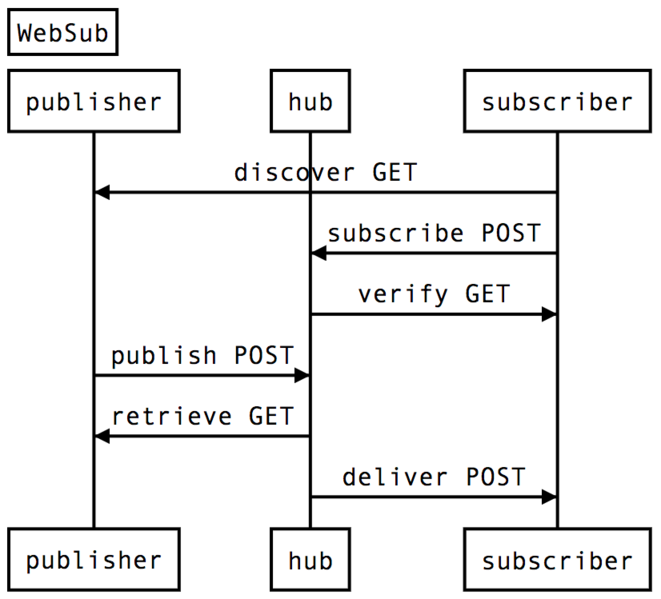
Deezer would identify the Hub serving a podcast while importing it, then subscribe to this Hub in order to be notified whenever this very podcast undergoes changes.
The podcaster, known as publisher, would notify the Hub whenever they update the podcast, therefore triggering a delivery from the Hub to Deezer.
Since a public API with no authentication is required for Websub (as per W3C specifications), for security and scalability reasons, we decided to containerize it within Kubernetes.
This development impacted multiple parts of our microservices stack, from the pull podcast importer to the Kubernetes app, while not forgetting the creation of a subscriber job and updates in our internal API.
We also had to add some safeguards to make sure the subscription intent would always be legitimate.
The whole thing can be represented with this sequence diagram:
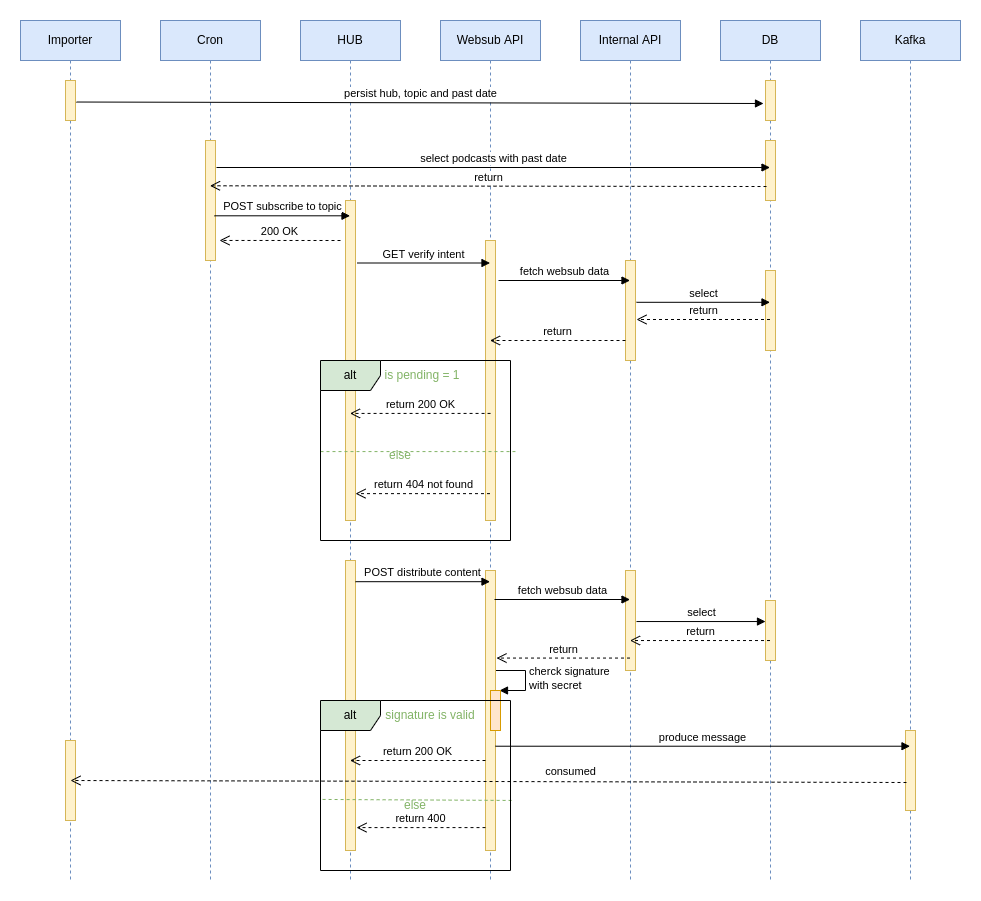
While this initiative was a success and dramatically reduced the number of podcasts still being pulled, the result in terms of ingestion delay was a little bit disappointing.
By observing the lastBuildDate or the last episode pubDate within RSS feeds and the timestamps of distribution requests as well as other data, we can assume that some podcast hosts do not notify the Hub on time or do not always notify the Hub whatsoever. We also have doubts regarding the accuracy of the pubDate and lastBuildDate tags in some cases.
Step 3: Parallelizing impactful steps
For a while we put into place some profiling of each step of the import process in order to identify pain points.
Unsurprisingly, the download of the RSS appeared to be responsible for a large part of the import time. We actually had to set up a 3-second timeout in the past because some feeds would take more than 30 seconds to load from some servers and would slow down the whole queue.
This is a fairly simple solution: we basically just download multiple RSS feeds in parallel on a temporary volume before importing their content.
We just had to tweak our configuration in order to find the sweet spot between the number of parallel downloads and the number of import workers.
Without changing the number of parallel workers, we’re now able to process around 3 times more podcasts than before in the same time span.
With that final step we finally reached the key results we had previously set!
Conclusion
We knew from the beginning that we wouldn’t have the means to achieve a 5 minutes flat check for each podcast like some of our competitors. Nor did we want to as it would be unreasonable and unecological.
Thanks to the work of the podcast community and our close relations with some podcast distribution platforms, we managed to develop solutions that not only prevent resources from being wasted but also allow real-time updates on a large part of our podcast catalog.
The mean delay for podcast episodes to be available on Deezer has been dramatically reduced, but the work doesn’t end here.
We must keep in mind that our podcast catalog will continue to grow at this rhythm, if not faster, and that a big chunk of it will eventually clutter the pull import again, which at some point will put us back in the situation we were in.
Importing podcasts massively is a long-term effort that requires continuous discovery and improvements, so we’re already preparing the next step…but that will be a story for another time!
Do you want to help us build and deliver the best experience on Deezer?
Take a look at our open positions and join one of our teams!


