




This year, Deezer’s recommendation team taught its feature Flow to recognize emotions in music. Here’s the story of Flow’s moods.
Co-authored by Benjamin Chapus and Théo Bontempelli

Flow me to the Moods: a little bit of context
The paradox of choice
The development of music streaming platforms in the late 2000s revolutionized music consumption: music lovers were finally able to have cheap and easy access to all the music in the world.
Although beneficial in so many aspects, this new bliss magnifies a problem for music listeners: choice overload. The abundance of options requires more effort from users and can leave them unsatisfied with their decision. Interestingly enough, before the implementation of Flow on Deezer, many users opened and left the app without listening to music.
Our teams first thought of a content issue: perhaps users couldn’t find the music they wanted to listen to? It took us a while to realize the problem was lying elsewhere: some users simply didn’t know what to choose. When faced with a catalog of more than 90 million tracks, choice soon became a burden instead of a gift. A new solution was needed. A solution to make choosing easier.
Flow, the magic play button
That’s why in 2014, Deezer introduced Flow, a magic button playing music that would adapt in real time to a user’s taste, mood, activity but also time, weather, location, you name it. A magic play button that freed our users from the burden of choice.
The first challenge — adapting to our users’ musical tastes and their evolution— was handed to our recommendation team, experts on the topic. As for addressing the other criteria, we were not quite sure whether we should ask the users for their input or if we should let “the AI” figure them out. In order to make the magic button as “magic” as possible and to keep the experience as simple as possible, we decided to try and let Flow figure them out.
These decisions and our recommendation team’s efforts seem to have paid off since for the last seven years, millions of music fans have steadily been using Flow to play and discover their favorite music.
Flow is now evolving
But you know, times they are a-changin… and what used to be magic is now taken for granted by evermore demanding Flow users.
Today, they’re expecting Flow to better adapt to their context…
And indeed, after years of iterations and AB tests, we’ve come to the conclusion that no matter how hard we tried, we didn’t seem to be able to fully hold Flow’s promise of adapting to the user’s moods and activities.
That’s why in October 2021, Deezer introduced Flow’s moods, a new feature that allows users to tell Flow how they feel, and enjoy music truly adapted to their mood. Let’s rewind on the development of this new feature, with the machine learning challenges associated with it.
Why Moods?
Asking users for their input
At first we thought Flow should “listen to the beat of your heart and help you find the songs that match it”. We thought the AI would guess your mood based on your interactions with the proposed tracks. The thing is, you can interact with a recommended track only in 3 different ways: either by liking it, banning it or skipping it. We had no problem interpreting the first two as they are pretty explicit, but it turns out that the most used real-time interaction in the player is the skip button. The skip button is a complicated signal to interpret because it is implicit: there are plenty of reasons why you would use it. You might not like the track, have heard it too much already, the timing could be bad, it could make you think of your ex, it doesn’t match your current mood…
So, if the system is trying to hard guess what to play after you skipped a track, it might not match “the beat of your heart” right off the bat.
If you’re curious about the details, you can consult a paper on the topic that was published by one of our colleagues (and actually helped convince the VP of Design that “the AI” would not figure out user’s mood based on implicit interactions).
The only other option was to ask users for their input, which we figured out a lot of Flow users were eager to do .
Getting emotional
However unique and diverse musical tastes they may have, most Flow users have a pretty similar approach to listening to music: they’re looking for music that matches their mood and activity. They don’t care so much about the artist, the genre or the history of the music that is playing as long as it helps them feel what they want to feel at that given moment. To them, music is a tool, a catalyst for life and emotions, it makes them work better, run harder, party longer… They see Deezer as an emotional jukebox, a remote control that helps them pilot their mood, through music.
Yet, in order to play music that matches your mood or context, you have to create your own playlists, which requires effort, or look for manually curated playlists on Deezer, which are not always perfectly suited to your personal musical taste.
We decided to allow people to explicitly tell Flow what kind of mood they were in. This would allow Flow users to effortlessly listen to music that matches both their personal taste and their emotional context.
What are Flow’s moods?
Reinventing the wheel
The beauty of Flow lies in its simplicity: a colorful play button on top of Deezer’s homepage. In one click, Flow provides you with the perfect musical experience: a delightful assemblage of your favorite tracks and beautiful discoveries. Always adapting to your evolution in tastes, always relevant, Flow doesn’t require you to think. Open Deezer and press play.
We now had to come up with a solution that would allow users to tell Flow how they felt so it would play music perfectly adapted to their emotional context.

This wheel allows you to choose between 6 moods, which cover the main situations in which people usually listen to music. Users can access it by clicking on Flow card’s cover on the homepage.

On desktop, since the interface allows for more space, we seized the opportunity to display Flow and all moods filters on top of the homepage to stick to Flow’s one-click to play experience.

Flow was now able to receive input on user’s mood. There remained the question of understanding and using this input.
Harvest Mood: how to detect a Mood?
Understanding the relation between sound and emotions
It’s easy to the human ear to feel the mood of a song. The first few notes of Ne me quitte pas by Jacques Brel will make you feel melancholic, while the intro of Good Times by Chic might make you want to get down on the dance floor. With such power over our feelings, comes great responsibility for the algorithm!
But fortunately, classifying music by mood has been a long time tradition at Deezer with the manual curation of thousands of playlists. Our users have a particular feel for our Mood Editor Alice’s huge playlist collection, which covers almost every situation you may ever face! But even with the highest will and motivation, it would take more than a century to categorize the 90 million songs of the Deezer catalog and catch up with the thousands of new albums that are delivered every week.
If the relation between music and emotions can be subjective, the perception of emotions in music is usually related to a combination of its acoustic characteristics. The presence of certain types of instruments, the choice of tempo, complex harmonies, and loudness are examples of attributes that will construct the musical mood of a song.
Of course, computers can’t understand emotions (yet? 😱) but we thought it may be possible to break them down for them, and let them learn the relation between typical musical signatures and the emotion they convey.
Learn by example
Machine Learning appeared to be perfect for this task because it gives a computer the ability to learn without being explicitly programmed. The idea was that by showing an important set of labeled examples along with their attributes to the algorithm, it would learn to recognize and generalize the audio descriptors associated with that label. The result model could then be used to predict the label for any new examples based only on the descriptive attributes that were used for training.
So the critical task was to build a reliable dataset that contained relevant musical descriptors for each song and their annotated mood. For the latter, the important collection of manually curated playlists of Deezer’s in-house editors was a good starting point: many playlists had been curated with a particular emotion in mind, making it easy to build a list of tracks for a particular mood.
Thanks to the Research Team at Deezer, we disposed of a huge variety of audio descriptors for every available song. Using music information retrieval and audio fingerprint techniques, we could get an insight of the different sounds that music is composed of. This is the kind of technology behind Spleeter, i.e. a source separation algorithm that can isolate instruments or voices, allowing the extraction of even more audio details.
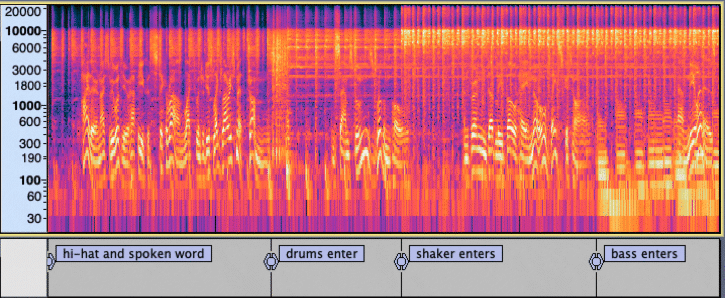
A music track shown using a Logarithmic Spectrogram.
In this view, the successive instrument entries can be visually observed.
The raw audio signal is transformed into a more digestible format called spectrogram for further analysis. This transformation creates an exploded view of the sound representing the intensity of different frequency ranges, letting the model actually visualize the sound and reveal its acoustic components.
The Deep Learning architecture used for sound recognition is very close to the one used for image recognition, mostly because they both work on pseudo visual representations.
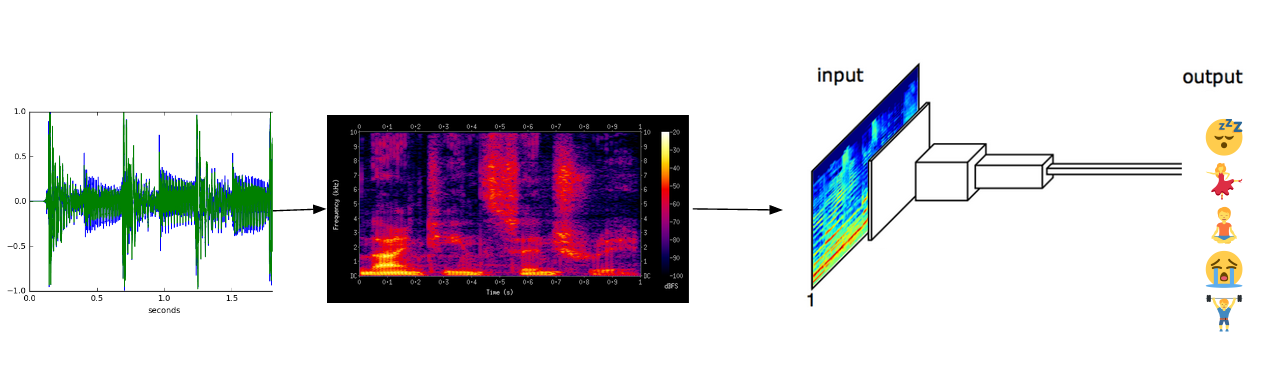
When our dataset with all song moods and their attributes was complete, we were able to start the learning process. This step can seem easy, but remember the model quality is generally as good as your input data! Many iterations and fine tuning were required to get a satisfying result, and particular care was taken regarding the variety of musical genres represented in the training data. For instance, if all examples of chill samples had been jazz songs, the model would eventually have learned to recognize jazz instead of chill properties, coupled with a bad accuracy on other genres.
After a few rounds of training and adjusting, the output model was able to extract mood features from the whole catalog, adding valuable metadata about the song’s audio content.
Let it Flow
Start with the user’s music profile
So now, what happens when a user launches their Flow mood? The first step is to choose a starting point for the musical journey, and to achieve this, we create a map of the user’s profile that represents their musical tastes. This model relies on an internal similarity model between songs or artists, learned from music metadata and the collective intelligence that can be extracted from all user listening behaviors. Its purpose is to create a similarity space in which tracks sharing the same properties are close to each other, while different tracks are far away.
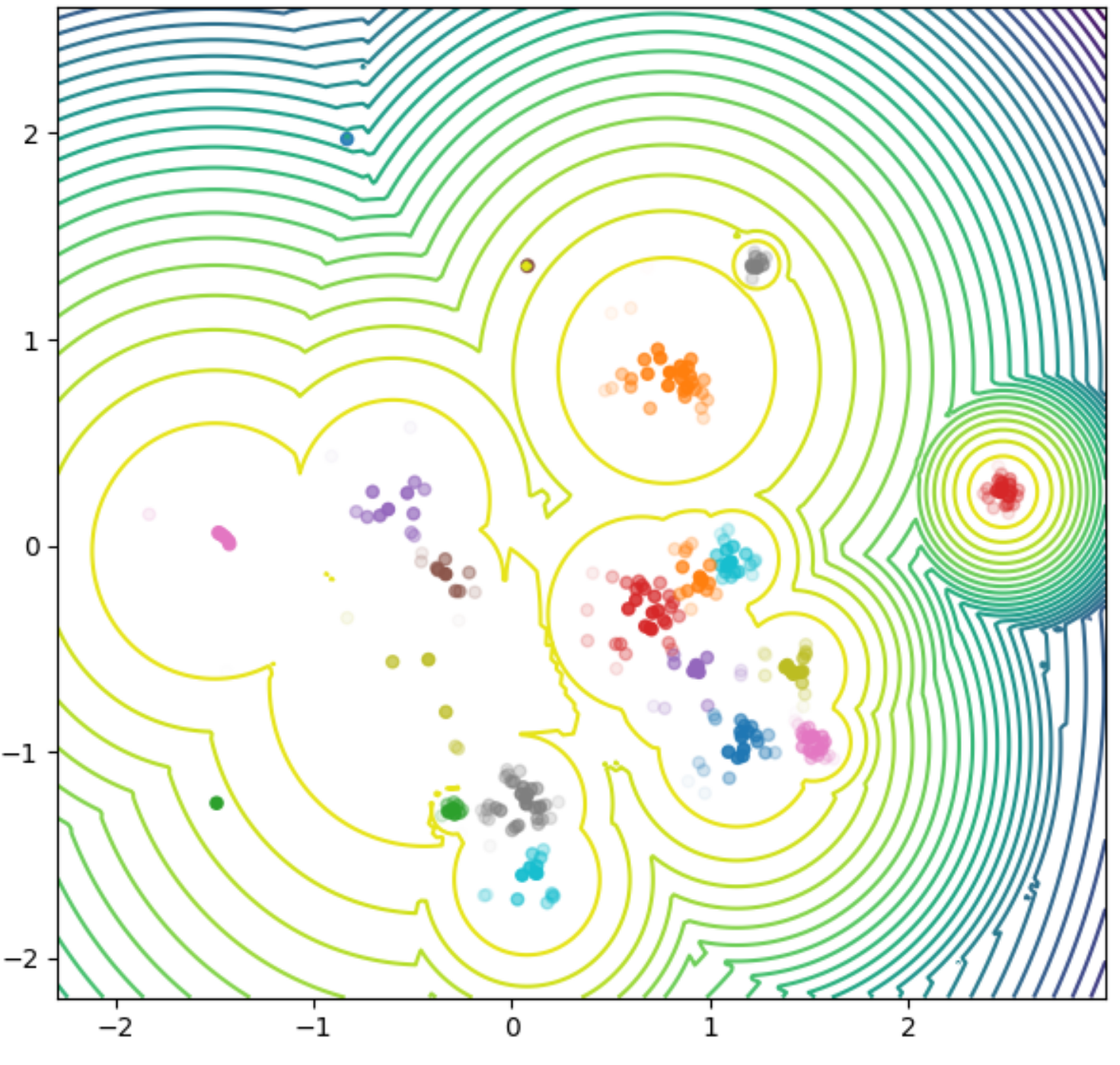
Example of modelization of the musical space for a user. This view reveals the different musical centers of interest of the user.
Projecting the user’s music collection to that space will reveal some dense areas corresponding to their personal music tastes, which constitutes good places to be visited by the algorithm. The map also contains information that indicates the principal moods in the area. This way, when a user selects a Flow mood, the system knows what’s the best place to start the listening session.
But for some users, it can be hard to find a good starting location for every given mood. Not everybody listens to party songs or Japanese ambient music! To solve the problem, the system can rely on a manually curated collection of tracks for each mood, used to augment the user’s music collection. These tracks are not randomly chosen though: they are reordered based on what users with relatively similar tastes listen to.
Explore and compose: these moods are made for walking
Once we have the starting location, we can start to explore around it to create a pool of tracks that we think the user will like. The underlying similarity model ensures that songs in the neighborhood of the chosen location will constitute good candidates for the mix.
This pool can contain hundreds of songs, and is refined by a final ranking model in order to only keep the most relevant items, based on how they fit the selected mood and user characteristics. The final batch of songs can be composed of some of the user’s Favorite tracks, old tunes they forgot they love and discovery tracks that are new to the user.
Of course, the mix is continuously updated, using user interactions as feedback to adapt the next batch of songs. For instance, when a user skips some track from a current session, the system will use the information to update its ranking model or even choose a new starting location.
Conclusion & future work
In this post we presented Flow moods, an emotional jukebox recommending personalized music at scale. Besides its promising performance, this system helps us study interactions between users and music. Moreover, future work will aim to improve Flow moods by examining more advanced models for music mood detection. For instance, while our current classifiers only rely on audio signals, we could consider complementing them with lyrics data and playlist occurrences. More details can be found in our accepted poster at Recsys 2022!
In the mood for new experiences? Check our open positions, join one of our teams and help us amplify the emotional musical journey of millions of users!


