




Some tips and best practices to structure your documentation and empower your employees to understand and leverage data without having to be data wizards.

People not reading documentation; a problem that may look familiar to you…
Documentation is a great way to convey information and knowledge for safekeeping over time and to help employees find solutions to their needs autonomously.
Sadly, having useful documentation can be challenging and complex to achieve. The usual pain points are faced by many:
- People who don’t read the documentation, despite the effort your teams put into it
- A messy structure
- Outdated pages
At Deezer, the Data Platform is the set of tools and services that, when combined, allow employees to ingest, process, visualise, and act upon data. In short, they are the tools used daily by Data Engineers, Scientists, Analysts, and many other people internally: Product Managers, business employees, etc.
The team in charge of the Data Platform has always had documentation in its DNA: documenting projects, decisions, and how-tos for internal users and our future selves.
Despite great content being available, the Data Platform documentation was a complete mess, and was failing its purpose while being impossible to maintain.
- It was incomplete — The documentation was spread over three different spaces, and it was difficult to put two and two together, even for the team.
Note: Confluence documentation is organised by creating spaces, which are aggregating pages under a navigable tree. - It was not discoverable — It was buried in a nested structure of old and mostly abandoned documentation spaces.
- It was not navigable — There was no logical structure; you could tell there had been unsuccessful attempts to organize in the past.
- It was not comprehensible — Everything was mixed up: technical documentation, team mission, rituals, incident reports, PoCs, etc.
Inspiration is key to finding great solutions
Categorising your content
Internally, we’ve been previously inspired by “The Documentation System” proposed by Divio. It is a great framework to structure your content into four categories, depending on what the reader is looking to accomplish:
- Tutorial: I am new to the tool, and I want a hands-on onboarding
- How-to: I know about the tool, but I wonder how to perform a specific task
- Explanation: I want to learn about architecture choices, advanced concepts, etc.
- Reference: I want to get an exhaustive list of all features/methods
The result is an easy-to-navigate structure in which the audience knows what to expect, and the documentation maintainer can be very specific, without having to create a “one-size-fits-all” page.
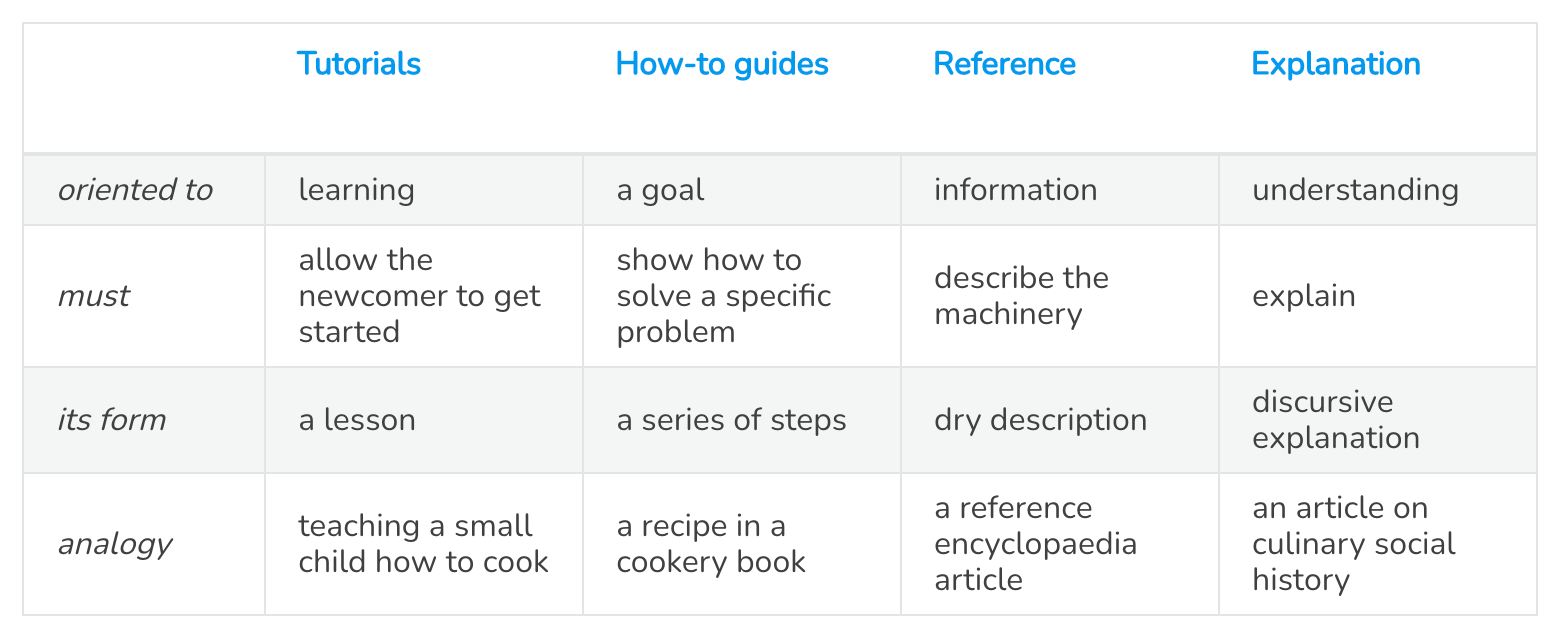
As the central data team, this framework matches our needs perfectly — the documentation must address all employees internally, meaning that each person must be able to find tailored content depending on their needs and expertise. For example, tutorials allow for newcomers/beginners to learn the basics, which is great for non-Data employees and data folks discovering new tools and services.
Adopting a Product approach for your Data Platform
Before we started, there were already 500+ pages, so even by splitting them into four categories, it would still be too much to discover and structure them easily. Think about finding a very specific How-to within a list of 125 articles: I bet that a hundred percent of people would give up before even attempting to go through the list.
Clearly, we needed to combine this approach with another one to limit the time spent looking for information while navigating.
Over time, adopting a Product mindset when developing the Data Platform became a habit. Reading “How We’re Building Our Data Platform As Aroduct” by Osian Llwyd Jones from Stuart Tech, inspired us to segment the Data Platform into Components (read “internal user facing data products”) and to apply the concept to our internal user documentation.
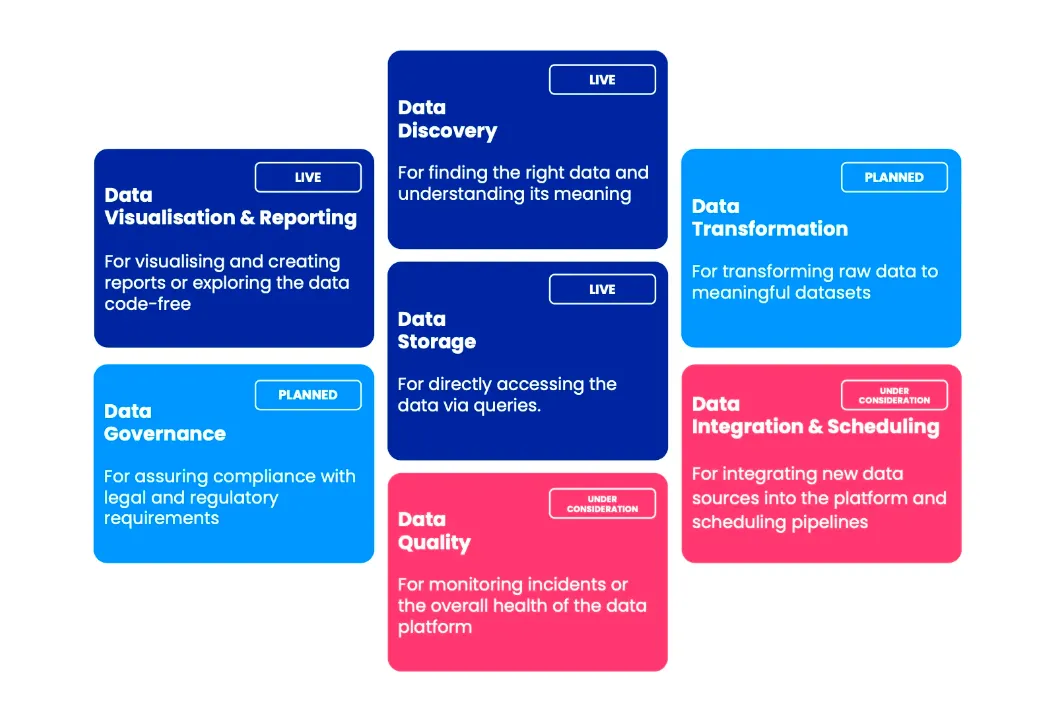
The main takeaway for our documentation space was to define internal user-facing data products so that people can easily relate to what they are trying to accomplish instead of reading through the names of obscure tech or third party solutions.
For example, if internal users were looking for data, they would leverage the Data Discovery component, which would likely be a Data Catalog solution that we would call “Interface”. The key idea is that components are standalone, but as part of the Platform, they usually work together to achieve an overall result. You can think of them as pieces of a puzzle.
What we came up with
With that in mind, a new documentation architecture was created in a dedicated documentation space. All irrelevant content (e.g., team mission, rituals, PoCs) were moved to designated spaces.
The Data Platform ended up being broken down into Components, i.e., what task I am trying to achieve.
Each Component is made of one or several Interfaces, i.e., which tool I will use.

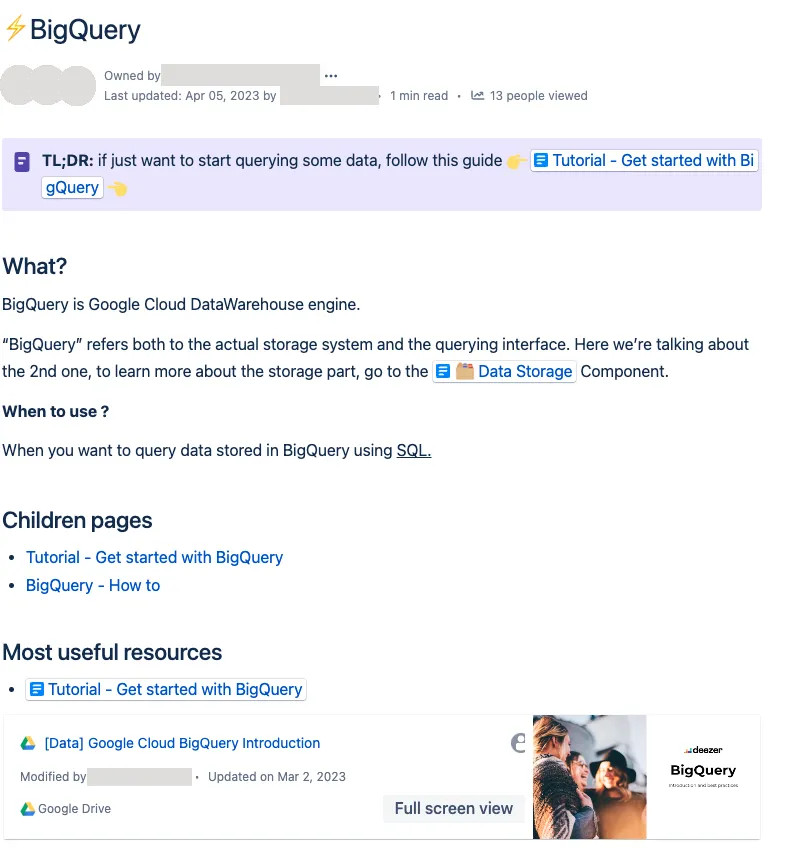
For example, I want to Explore Data, so I will use BigQuery or Notebooks.
Each Interface follows the same structure where documentation pages are grouped into one of four categories depending on their aim, as depicted by the Documentation System.

To further support readers, in several pages, we’ve highlighted the expected audience that could benefit from it, that is to say, be capable of understanding it fully.

In addition to this structure, two key pages were added at the top of the documentation space:
- A page to understand how to explore and navigate through the space, highlighting the concept with concrete examples
- A page explaining the Data Platform architecture, detailing each component in a few words from an internal user perspective

Our secret recipe to perform a large scale documentation migration
Moving a 500+ page documentation spread across multiple spaces is no easy task and requires a great amount of time and effort. Especially because some of the pages were completely outdated, some partially outdated, with some being a mix of high level content and very precise technical content.
In a nutshell, the project went through the following phases:
- Definition — Iterating over the concepts and high-level ideas behind the structure, presenting to the team and getting feedback
- Converting the idea into something concrete — Quickly creating a first iteration of the structure within our documentation tool to bring it to life
- Aligning and getting used to it — A few pages were taken as examples, and migrated during all-hands team meetings to get the hang of the new structure
- Migration phase — The workload was spread on the team evenly
All team members were assigned with:
- a subset of the documentation to migrate
- Components and Interfaces to explain

Each page up for migration was either archived or updated. If kept, it had to be put under the correct Components, Interfaces, and then the correct Category.
Success metrics were tracked as part of the migration phase:
- Percentage of pages migrated or archived
- Number of Monthly Active Readers
- Number of remaining new pages that needed to be contributed
The main takeaways from our migration are:
- Iterate and Experiment — It’s impossible to nail the perfect structure from the get-go. Put your ideas in ink, share them with your team, and test them against concrete examples. You will always find examples that don’t fit perfectly with your ideas. Don’t let this slow you down; you can deal with them later.
- Be bold — Keep only what you need — When refreshing documentation spaces, it is likely a big chunk of the documentation is useless. Delete pages if you are confident that they are not of use. Otherwise, archiving is often the way to go, especially if you have doubts: documentation can still be brought back easily, and is still indexed in the search on Confluence.
More than half of our pages were archived as they referenced outdated tools and practices that were in use back in the days, when data processing was performed by our on-premise Hadoop cluster.
- Keep it simple — This project was already a big effort, so in order to be successful, we decided to drastically limit the amount of new content produced, compared to what is actually necessary: explaining the overall architecture, detailing the Data Components and Interfaces.
- Go big or go home — A documentation is an important piece of knowledge that will guide your teams over the next months and years. A migration must be treated as any other software project and be fully completed, otherwise, you will only be adding another layer of complexity. I recommend making it a team objective.
- Monitor usage — Maintaining good documentation but having no readers is pointless. Make sure to onboard people in your space, progressively taking feedback into account. You might discover that some unexpected pages can attract a lot of viewers. When moving forward, leveraging usage metrics could help you determine which pages are worth maintaining.
- Get feedback and work together — Producing qualitative content that is understood by a majority of people is key. To do so, your documentation will need to be reviewed, just like you would do with your code. In our case, we worked with a simple spreadsheet, progress statuses, etc., to organise and follow up on reviews. Feel free to choose whatever works best, depending on your team setup.
What we achieved
- Centralization — There is now a single entry point for the Deezer Data Platform documentation space
- Easy discovery — It has a clean structure allowing any employee to navigate and leverage data
- Up to date — A hundred percent of existing pages were migrated, archived, and updated in less than 3 months as a team effort. The number of pages was divided by two, heavily reducing the documentation we need to maintain
- Actually read by people — Our goal was to reach 45 of the 60 Data users (Data Engineers, Scientists, Analysts) by aiming for an average of 45 Monthly Active Readers on the Confluence space. It consistently reached 100+ Monthly Active Readers for more than four months after the launch. Our biggest surprise yet? The documentation has been heavily accessed by non-data employees.
And now what?
Well, you are never really finished with documentation:
- Focusing on keeping it up to date — Now it will be easier for the team to find and maintain related pages thanks to the structure. But, it takes rigor to update the documentation every single time though. So, as a result, we’ve decided that it would be part of the Definition of Done for all our tasks, meaning that documentation must be updated whenever something is changed.
- Missing pages will need to be contributed — This migration showed that the current content is mostly aimed at data experts, and we know we’re already good at producing content for them. Less technical users remain an audience that is not addressed fully, but it would be highly beneficial for them to have access to basic data knowledge. Therefore, in the next months, we aim to empower Deezer’s Product & Tech teams to answer basic data needs (e.g., finding trivial metrics, creating a basic dashboard, monitoring, and finding issues within data).
- Iterating on the structure is ongoing — Iterating will continue to be as necessary now as it was when developing the documentation. Unexpectedly, we’ve had to merge, split, and create Data Components here and there over time, always with the aim of making things easy to understand.
Despite the fantastic results, we continue to receive questions on a daily basis on our Slack support channel. The next step would be to leverage the latest improvements in AI to surface high-quality content directly on Slack by having a bot answer or redirect internal users.
As a matter of fact, Atlassian is currently building its own bot called Atlassian Intelligence that will leverage Confluence knowledge to support people on Slack. Concurrently, many other people are starting to contribute support bot based on generative AI.
The future looks great, but it surely starts with a good documentation designed by and for humans, whether readers or editors.
Special thanks to Eloi Fontaine, former Data Product Manager at Deezer, who played a key role in shaping up the space, and to the Data Operations team for making it a success!
Additional thank you note to this article’s reviewers Pauline, Elisa, Paul, Eloi and Gillian.


