




At Deezer, the R&D department role is to perform scientific research in order to help the production teams develop new cool features as fast as possible. The team consists of researchers in signal processing, natural language analysis and machine learning as well as software engineers.
Every once in a while, we all stop working on specific topics and unite our forces during a few days for what we call internal hackathons. The goal is to take upon a subject of interest for Deezer, explore it in details and implement a mockup prototype. The last hack was about voice control and this is a resume of what we learned.
Context
Voice control could be the next big thing. Amazon, Google, and others seem to be convinced enough to invest heavily on speech recognition software and now, dedicated hardware too. The success of Amazon Echo and the launch of Google Home show that this market is expected to be growing fast in the next years., at least by some big players.

How those technologies work.
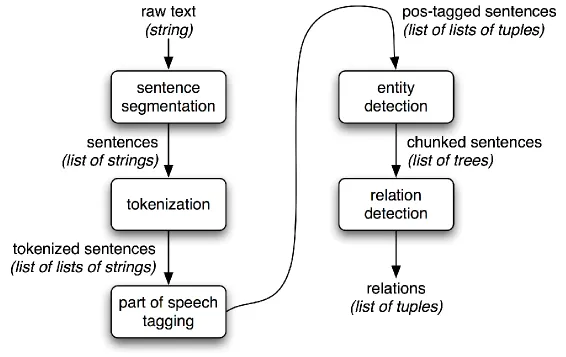
In order to transform spoken words (user’s speech) into a Deezer command, one has to go through several operations described in the figure below:

Recording
First, you need to capture the speech into a digital audio signal. This is called recording and requires a hardware device such as your smartphone, a computer microphone or an Amazon Echo for instance. The quality of the captured audio is of importance, so the recording conditions must be carefully taken care of. In a noisy environment, the captured signal may be very hard to exploit. To isolate the voice from the background noise, specialized devices such as Echo use Noise Cancellation techniques.
Since Deezer is not going to start building its own recording devices anytime soon, we will just assume that the microphone used will be the one of the user devices.
Transcription
Once you have a digital audio signal, the next thing to do is convert it into raw text and this is the transcription part. The fruit of decades of research, it is a tremendously complicated problem that requires taking care of the huge variability of the input signal. Think of all the different ways to pronounce a single word like “Play”, at different tones, speed, loudness, with various voices and accent. Now things are even harder at a sentence level. Current technologies require massive amounts of training data, that is, several thousand of hours of speech being manually transcripted to “train” the automatic system.
Only companies of the likes of Google, Apple, IBM, Microsoft or Amazon have access to such resources. We at Deezer, certainly don’t :-). It means that whatever technical solution is chosen, we are always going to be relying on external software to perform the transcription. Because they want developers to use their technologies, most of the pre-cited companies provide APIs for speech transcription. For instance, you can send an audio Wav file to the Google Speech API and get the result of their transcription as text.
Of course, such services are paying ones
Parsing
Finally, the parsing consists in performing a structural analysis of the text. Basically, it means identifying tokens, then guessing what each token role is in the sentence. Take the following sentence :
“Play Billie Jean By Mickael Jackson”
This sentence will first be tokenized as :
[“Play”, “Billie”, “Jean”, “By”, “Mickael”, “Jackson”]
Then the syntactic parser will understand that “Play” is a verb and that “Billie Jean By Mickael Jackson” is actually an object. This object is also composed of two elements “Billie Jean” and “Mickael Jackson” joined together by the connector “By”. Finally, the parser should understand that the group “Mickael Jackson” describe a person while “Billie Jean” is the title of a song and they are related to each other because the first created the second. This final step is called entity detection and relation detection and yes, it is also not easy at all!
The full process is much better explained in the nltk project documentation from which I borrowed this summarizing picture:
Finally, the execution part will be achieved thanks to the Deezer SDK and APIs.
Hackathon Objectives
If I summarize, building a voice control system amounts to building bricks that are all rather complicated and would necessitate months of R&D in order to be developed internally. Since this hack was meant to last just three days, we adopted a different strategy: use and test existing technologies. We thus focus on comparing systems built with various bricks on a set of voice commands and see what exists, what works well and what doesn’t.
Choosing the technologies
We started this hackathon by performing a wide survey of existing technologies. The state of the art is complex because companies now ship multiple bricks together. For instance, the Amazon echo API perform both the transcription and the parsing in the same brick. Which means we cannot test those them separately. Microsoft Cortana goes even further to execute the command on your app. Google Cloud, on the opposite, exposes two different APIs so we can evaluate them independent of each other. Overall we listed:
- Google Speech API Performs the Transcription. Inputs audio file, outputs raw text
- Google Natural Language API Performs the parsing. Inputs text, outputs a list of objects and their types (track title, artist names, etc.)
- Amazon Alexa performs both the transcription and the parsing. inputs your voice directly if using the Echo device, or an audio file via api, outputs a list of objects and their types (track title, artist names, etc.). When using the Echo device, can also execute pre-defined commands.
- Microsoft Cortana Perfoms both the transcription, the parsing and executes command.
- IBM Watson Speech API Performs the Transcription. Input: Any wave file, Output Raw text
- IBM Watson AlchemyLanguage Performs the parsing. Input: Text, Output: list of objects and their types (track title, artist names, etc.)
And this list is far from being an exhaustive one.
We chose to focus on Google APIs, because they are of very good quality and available through web request but also natively on android devices and on the Amazon Echo device through the use of the Alexa API.
Test Sentences
Comparing approaches mean we have to design a set of sentences that will encompass the commands we want to support. We separated them in three types, ordered by increasing complexity:
Basic Commands:
Correspond to the Deezer Player Available Controls : “Play”, “Pause”, “Stop”, “Resume”, “Next”, “Skip”, “Previous”, “Volume up”, “Increase Volume”, “lower Volume”, “Volume down”, “Mute”, “Unmute”
Understanding those commands require little more than recognizing the words, which means any good transcription system should be enough to allow these interaction.
Music On Demand Commands
For instance, play a specific track: “Play Losing My Religion”, “Play Jeremy by Pearl Jam”, “Play Uptown Funk by Mark Ronson”, etc.
Play a specific Album: “Play Waste a Moment by Kings of Leon”, “Play Dark side of the Moon by Pink Floyd”, etc.
Or play tracks by a specific artist: “Play some Rihanna”, “Play Beyonce hits”, “Play some Chostakovitch”, etc.
Or start a specific playlist (e.g. one from the user): “Play playlist Carcolepsy”, “Play playlist Alternative classics”, etc.
Those are already much harder because there is a syntax and objects roles that need to be recognized and mapped in Deezer Catalogue.
“Leanback” Commands:
For instance: “Play some Pop Rock from the 90s”, “Play some minimal techno”, “Play Pop Rock from the 90s”, etc.
These commands are even harder to process because the concepts involved are not directly mapped to objects of the catalog but rather as a general semantic description of the content.
What was achieved
We certainly discovered and learned a lot of things during this hackathon. We tested many solutions, took some up to the integrated prototype level, played a lot with the API in general and the Search endpoints in particular.
At the end of the hack, a working prototype was finished. For now, it only works internally at Deezer, but it sure sparked a lot of interest within the company.
Custom Syntactic Parsing
In the team, Francesco is working on language topics and so naturally he took the subject as a challenge. The advantage of having a Francesco is that he does not fix boundaries a priori on what we can do. Instead, we need to define scenarios and he will build the parser to solve them.
During this hack and based on a set of NLP tools that he has been developing, Francesco built a smart parser that we can use in the following manner:

For those not used to reading code, what you see here is a practical example of the result of our custom parser. Given an input text, as should be returned by a transcription system, this parser is able to determine which part is the action command and identify various resources such as artists, track titles or general tags describing music.
Lessons Learned
First of all, getting a clean speech recording is essential for such systems. This advocate in favor of putting some effort on the hardware part, because thus one can control the quality of the signal used as input of the transcription stage.
Recognizing artist names or song titles is hard
But clean speech is not enough. We found the transcription stumble upon a major difficulty: retrieving artist names or song titles is hard. Google does it quite well for famous ones, but smaller artist names are usually not correctly transcribed by the systems we tested. This is a very serious limitation because remember: if transcription fails, then parsing will fail and the command is bound to be a failure too.
On the bright side, we have developped custom approaches for the parsing and resource matching that seem to be quite usable in practice. We intend to still work on them because it could enable rich interactions in the Deezer product.
Open Scenarios and Call for your Ideas
Most of all: we must extend our use cases and imagine new ways to interact with deezer through the voice. We have ideas listed below, but we are most of all eager to get feedbacks and the fruits of your imagination on this. So far we have :
- Flow Interaction: imagine flow start playing a Jazz tune, but you’re not in that mood, you could just say: “Hey Flow This tune is too quiet I’d like something more dancing” or on the opposite you are in a quiet drink with your friend, Flow starts playing one of your hard techno secretly loved tune and you could say: “No no, stick to the previous mood please”. These scenarios are very challenging but I think they are really interesting for the “lean back” experience.
- Search by lyrics. I can’t remember a song or an artist, but I know the lyrics were “Oh baby, baby, I was I suppose to Know ..” I could just ask Deezer to retrieve it from those lyrics! We actually have all necessary bricks to build this.
The rest is up to you. Help us identify situations where you don’t want to or can’t reach the phone/computer but need to change something about the music. How would you express it ?


