




TL;DR
I went to ICASSP in New Orleans to present a (small) part of the research done at Deezer in the R&D team. It was the opportunity to exchange with the community and gather much valuable knowledge and ideas. Our work was about using Convolutional Neural Networks (CNNs) to solve a lossy codec usage detection problem.

What’s ICASSP and why go there ?
ICASSP is one of the largest conference on Signal Processing in the world. Signal Processing is a broad subject; it includes sounds, images, biomedical data, sensors and radars. A key feature of this conference is the mix of theoretical work with more applied research. People from every continent gather to share about their latest research and learn from others. This year it was in New Orleans, cradle of Jazz and arguably one of the best place in the world for lovers of live music.
During a full 4 days of talks, over 1300 differents research papers are being exposed, either on 20min oral presentation or on poster sessions. The conference is rather intense; you find yourself running from presentation to presentation to gather as much knowledge as you can. I focused on the topics we’re the most interested in at Deezer R&D: Music Information Retrieval, Deep Learning and dimensionality reduction techniques such as matrix factorization and embedding learning.
General Impression

The last time I went to ICASSP was five years ago, I was still a phD student then, so this was a great opportunity for me to witness how my field of research has advanced in this time. The two most obvious changes to me were:
- Hard tasks, such as musical transcription, music source separation or audio classification are being addressed in much more effective ways nowadays and the improvement in quality is very impressive.
- Deep learning has taken over the signal processing field quite extensively. ICASSP 2012 had zero sessions about it; five years later there were 7 sessions specifically focused on it, 2 tutorials and numerous papers using deep learning techniques — ours for example!
Our Work: “Codec independent lossy audio compression detection”

The work we presented emerged from a problem that you could only encounter at a place like Deezer. As such, it attracted a lot of interest since the challenge was quite new:
Can we detect that an audio signal has been altered by a lossy codec ?
Let’s start with the distinction between Lossy and Lossless audio codecs.
Deezer audio catalog is delivered to us by rights owners in the FLAC format, which is usually a compressed version of the reference CD file (16-bits encoding, 44Khz sampling rate). Although compressed, FLAC is a lossless codec, which means once decoded, the raw signal is exactly equivalent to the original one. Think of FLAC as a zipped version of a text file that can be unzipped without losing content.
Lossy compression, on the other hand, will also compress the audio file but will modify the signal in a non-reversible manner, typically producing a much smaller file. Think of it more as a JPEG version of an image. Audio being a rather big media, compression is actually a huge deal, saving storage space, transmision bandwidth and ultimately energy and money.
Among lossy codecs, the most popular are perceptual lossy codecs such as MP3, AAC, Vorbis, WMA, AC3, etc. All of them use the following principles:
- Firstly, the signal is processed by a filterbank (typically MDCT) to deal separately with each frequency range.
- The second step is the quantization process, where the loss occurs. The principle is simple enough: high-precision coefficients will be approximated by numbers with lower definition that are cheaper to encode. The larger the approximation, the cheaper it gets but also the larger the loss of information and signal distortion. Codec efficiency is typically judged in terms of this Bitrate/Distortion ratio.
- The quantization is informed by a psychoacoustic model to make sure the approximations have a limited impact on the perceived quality.
- Finally the quantized coefficients are transformed into bitstream for final compression. This operation is fully reversible at the decoder side.
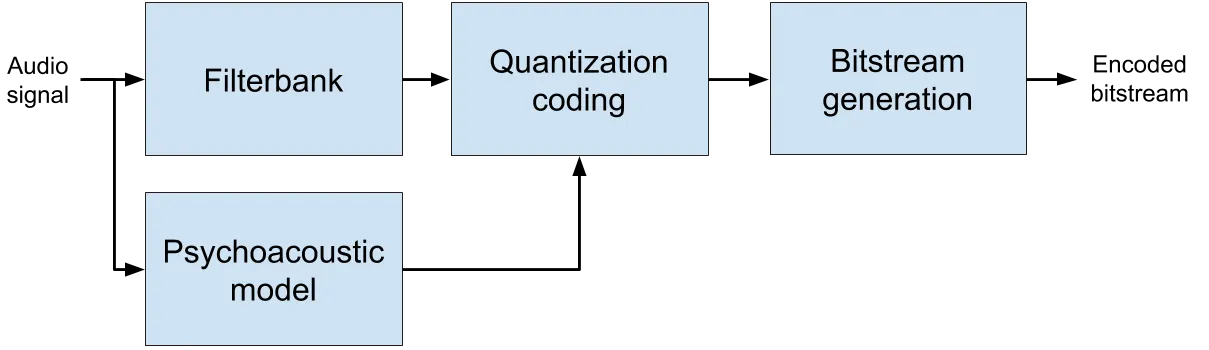
Perceptual Lossy codecs are able to compress a signal by saving space in time-frequency areas where the impact on the perceived quality is the lowest possible.
What distinguishes the various codecs is how each of the above block are implemented and parameterized. Another critical factor is the output bitrate (expressed in kilobytes per second or kbps) which will limit the size of the compressed file and therefore the quality of the audio. When referring to a compression scheme we typically specify both the codec family and the bitrate used. For instance you can use MP3@320kpbs, AAC@256kpbs, WMA2@128kbps and so on so forth.
The problem
If everything goes right (and it usually does) we get FLAC files that are truly unaltered audio. But sometimes, the FLAC itself is just a re-encoding of a signal that has been altered previously. Imagine the following pipeline:
- An original file A.wav is compressed in MP3 format, which outputs A.mp3
- A.mp3 is decoded back to wav. This gives Abis.wav an altered version of A
- Finally Abis.wav is encoded to Abis.flac and delivered to Deezer
Now because of the lossy MP3 compression, Abis.flac is not equivalent to what a direct A.flac would have been. The question is thus: when we receive Abis.flac can we detect that it went through the lossy process at some point before? if so can we do it irrespective of what the codec or bitrate were?
Proposed solution: Time-frequency modeling and Deep Convolutional Neural Networks
The key to solving the problem is to understand the impact of lossy compression in the Time-Frequency domain. If you are not familiar with Time-Frequency Transforms (TFT) and spectrograms, you’ll find plenty of material online to explain it. I like this video for instance; if you want to skip the math and just grab a graphical idea, jump to 4:26. If it’s still too difficult, check the wikipedia spectrogram page.
What is really interesting with spectrograms is that the impact of lossy compression is clearly visible.. at least for a trained eye! See for yourself -below is a picture where we have highlighted the key artifacts typically created by lossy codecs:

The picture above exposes three typical artifacts of perceptual lossy codecs:
- High frequency cuts: human ears are not designed to hear sounds with frequencies above 20Khz and this higher bound tend to decrease as one ages. The quickest gain for a codec is thus to remove the highest frequencies.
- Breaks between bands: codecs will typically process big TF chunks of audio separately, thus different quantization strategies at different frequency range can produce these discontinuities in the spectrograms.
- Clusters and Holes: Finer psychoacoustic effects take advantage of the way our ear is able (or more importantly not able) to process a sound when it occurs right after (or before) a powerful event such as a snare hit. This phenomenom goes by the name of pschoacoustical masking. Pretty much in the same manner our eyes have an intrinsic latency by design, our ears also experience some delays in our ability to process sounds. A smart codec will leverage this to gain space in those areas, thus creating holes and isolated clusters in the spectrogram.
Practical solving: training a classifier
Now that we know what to look for, we are going to train a classifier to discriminate between altered and unaltered files. We do so by building a convolutional neural network (CNN). Given the current hype around AI in general and Deep Learning in particular, you’ll have zero difficulty finding resources online about CNNs. The one we built takes spectrograms as input and outputs a binary label: altered or unaltered. We train it by showing it a large number from both sample classes so that it ends up making very few errors, as the table below shows:

Our system achieves very good performance scores, higher than all state-of- the-art methods that we found in the scientific literature. When it fails, it is mostly on cases where the decision is difficult because the lossy codec has a very high quality output (typically AAC@320kpbs). At those bitrates, artifacts are very weakly perceptible in spectrograms.
Interested readers will find more details in the paper itself, especially on how we build the dataset and additional experiments showing the robustness of this method to codec and sampling rate changes. But to sum it up, it works pretty well provided you carefully design your processing pipeline (spectrogram and neural net) and leverage the access to a sufficiently large amount of training data.
Conclusion
ICASSP was great. The community as a whole is embracing deep learning techniques to achieved performance jumps on hard, challenging tasks. Through our participation, we saw that our work at Deezer R&D is pretty much in sync with what’s happening out there. We’re confident that we’ll be able to contribute even more in the future.
Aside from that, I suspected New Orleans was great, but it’s actually awesome. I just didn’t know how much one could miss it, even so I could have guessed from what the great Louis has been singing.



