




In a nutshell
We’ve done some research about how to automatically detect explicit content in songs using only the music itself, and no additional metadata. Since it’s a sensitive and subjective issue, we did not want to use a black-box model, but rather build a modular system whose decisions can be traced back to some keywords being detected in the song. Our system gives promising results but we do NOT consider it fit for tagging songs as explicit in a fully automated manner. This work was jointly conducted with Telecom Paris and the full paper has been accepted for publication at the ICASSP 2020 conference.
Let’s be Explicit
When it comes to figuring out what explicit lyrics are, there is no general consensus. It’s obviously a cultural issue, with lots of considerations about the intended audience and the listening context. As is the case with movies, the primary objective of tagging a piece as “explicit” is to provide guidance to determine how suitable it is for an intended audience. This is often referred to as “parental advisory” because the audience in mind are mostly kids. If you’re interested, there have been scientific studies regarding the impact of explicit content on children, but that’s not what our research is about.

There’s a pretty good Wikipedia article about the creation of the parental advisory label for music. Despite its loose definition, it is generally admitted that strong language (curse words and sexual terms), depictions of violence and discriminatory discourse fall under the scope of what’s not suitable for children to hear in a song and should, therefore, be marked as explicit content. Of course, this definition is open to various interpretations.
As of today, only humans make decisions on whether a song should be tagged as explicit or not. The person in charge of this is typically someone who works at a music label and follows internal guidelines set forth by the company. When songs are delivered to streaming services like ours, they are sometimes accompanied by the “explicit” tag, and sometimes not.
When no tag is provided, it can mean that the song is suitable for all audiences, but it can also mean that no decision was made on the label’s side regarding its explicitness. There is a substantially large part of our catalog that falls under this category.
Before asking ourselves whether we could build a system that could do this automatically, by analyzing the music, we studied the problem from a human point of view. Having to decide which track should be tagged as explicit and which shouldn’t is a complex task, it requires a high-level understanding of cultural expectations and involves a lot of subjectivity.
Explicit Content Detection as a Scientific problem
Let’s take aside the above considerations and now just assume that there exists a deterministic method to decide whether a song should be tagged as explicit or not. The purpose of our research is to try to discover this method.
The problem can be framed as a binary classification one: Given a song X, can we come up with a function f that will output either 1 if the song is explicit or 0 if it isn’t? For instance, if X is “All Eyez On Me” by 2Pac, we expect f(X)=1 while if X is this song, then f(X)=0.

Like most classification tasks nowadays, it may be a good idea to use supervised machine learning (ML) techniques.
A modular, explainable approach
If you were asked to label songs as explicit or not, how would you proceed? A natural answer is to look at the words that are pronounced by the singer(s); if “explicit words” appear in the lyrics then the explicit label should be applied. That’s a simple answer, but arguably, that’s the best one, based on recent research that compared it to more complex machine learning approaches.
Now, what if you don’t have access to the text of the lyrics? That’s actually pretty common when dealing with millions of songs. If you are a machine learning aficionado, you might say: let’s build a big annotated dataset and train a supervised classifier to do it from audio. This approach is be called end-to-end or sometimes black-box ML. One family of such models are deep neural networks. They have been used with great success on classification tasks of images, sentences, videos and of course, music.
However, a common fallback is their lack of interpretability. Indeed, once the system is trained (e.g. by making it learn from an annotated set of examples), it’s not easy to explain how it makes its decisions on new samples that have not seen during training.

While we can evaluate the performance of the model on the set of known examples, one cannot easily associate its output to tangible elements of the input, such as musical features, or sung lyrics. We did try nonetheless this black-box ML approach, but we also wanted to try out another system more reliable, whose decisions could be easily justified. Such system is usually called explainable ML.
Fortunately, on our team, we have a PhD student, Andrea Vaglio (jointly supervised by Telecom Paris — Image Data and Signal Department) who is working on extracting lyrical information from music. One way to do explicit content detection is by first getting a transcript of sung lyrics, and then just using the presence or absence of words from an “explicit language” set to decide whether to label the song as explicit or not.
Getting an exact transcription from a singing voice mixed with music is a very challenging task. It’s already much easier if you can extract only the vocal part of the song. At Deezer, we developed a tool called Spleeter. It is freely available for everyone to use and does quite a good job at extracting vocals from songs.
Still, detecting uttered keywords from singing voices, even when isolated, is a complex problem, and much of our contribution here is to propose a system to do just that. It is called a Keyword Spotting System and is the main contribution of this work.

Once you have the probability of presence for all words in your “explicit” dictionary it becomes easy to make a decision. We use a simple, binary classifier for that, whose outputs can straightforwardly be linked to the “explicit words” presence probabilities.
Balancing for Music Genres
One of the usual pitfalls of doing machine learning is when your model doesn’t learn what you think it does, but only adapts to a bias in your sample data. In music analysis, this phenomenon is called a “horse”. In the case of explicit content detection, the most important bias to consider is on the music genres.
It won’t surprise anyone that many rap songs contain explicit lyrics. More than country songs, for instance. Yet, there are non-explicit rap songs and there are explicit country songs. If you’re not careful when designing your experiment, you may end up with a system that instead of detecting explicit lyrics, will detect rap songs, just because they have, on average, a higher probability of containing explicit lyrics.
To avoid that, we need to balance the data to remove this music genre bias. In practice, you need to train on as many explicit rap songs as non-explicit ones, and the same for all music genres.
Results
In the paper, we compare our modular approach with a black-box one, and with an oracle system that knows the lyrics and detects the keywords directly on the text (think of it as the upper bound of what we can achieve, if our keyword spotting system was perfect).
You will find all the details on the experimental setup in the paper but here’s the takeaway findings: Although it’s not as good as the oracle one, our approach produces quite promising results. Cherry on the cake, it beats the black-box model, which is always a nice result to have and goes against the commonly found belief that there is a trade-off to make between accuracy and explainability of an ML system.
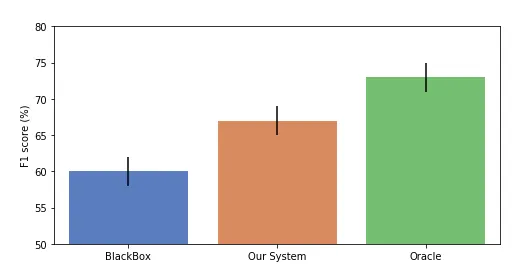
As a side note, we found that actually none of the systems considered reached levels of accuracy comparable to human ones. Even the oracle system only has an F1-score of 73%. This is an important fact to consider, especially when taking into account the sensitivity of the task. At this point, it’s not realistic to fully automate a decision process for explicit content labeling.
A final word
We investigated a first ever (to the best of our knowledge) approach to build an explicit content detector purely based on audio. Despite reaching some encouraging results, we’d like to emphasize that this task is not satisfactorily solved by machines as of today.
At Deezer, we give our partners, music providers and labels the possibility to mark the song they deliver to us as being explicit. Then users have the possibility to filter content based on this label. In this process, we just implement a user defined rule, based on the metadata we get. We do not intend to intervene in this process or to make decisions in place of either partners or our customers.
One could nonetheless use our work to build a system to assist humans in their labeling tasks. With our approach, we can not only detect the presence of explicit keywords but also know where they occur in the song. We could, therefore, highlight some parts of the audio to an annotator to facilitate his task. In a broader perspective, our goal is to gain knowledge on millions of songs and leverage that to improve the Deezer product. This research is another stone in this building.


