Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation

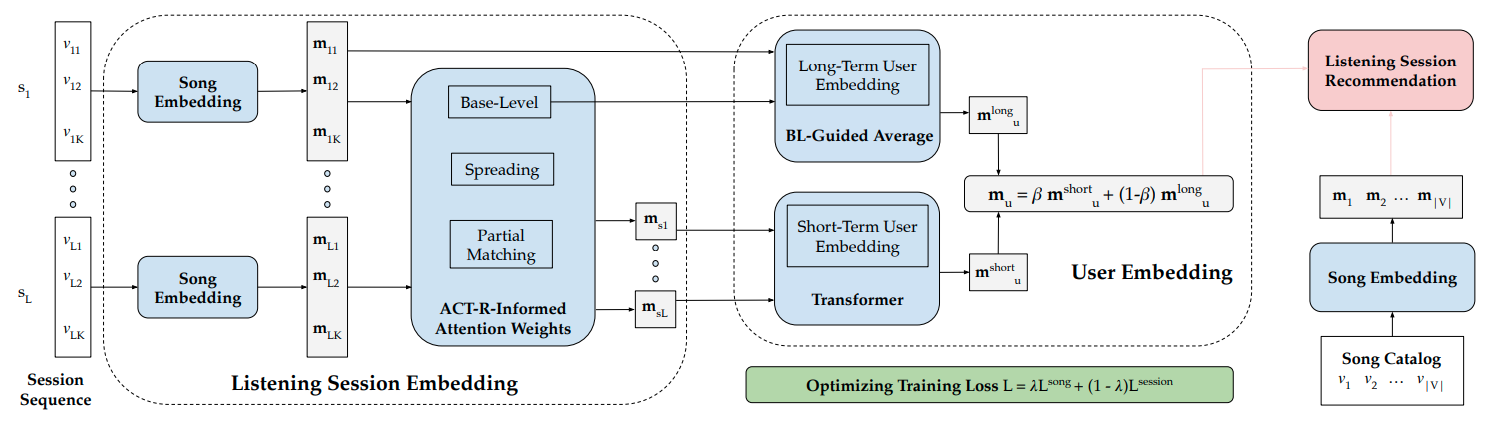
Music streaming services often leverage sequential recommender systems to predict the best music to showcase to users based on past sequences of listening sessions. Nonetheless, most sequential recommendation methods ignore or insufficiently account for repetitive behaviors. This is a crucial limitation for music recommendation, as repeatedly listening to the same song over time is a common phenomenon that can even change the way users perceive this song. In this paper, we introduce PISA (Psychology-Informed Session embedding using ACT-R), a session-level sequential recommender system that overcomes this limitation. PISA employs a Transformer architecture learning embedding representations of listening sessions and users using attention mechanisms inspired by Anderson’s ACT-R (Adaptive Control of Thought-Rational), a cognitive architecture modeling human information access and memory dynamics. This approach enables us to capture dynamic and repetitive patterns from user behaviors, allowing us to effectively predict the songs they will listen to in subsequent sessions, whether they are repeated or new ones. We demonstrate the empirical relevance of PISA using both publicly available listening data from this http URL and proprietary data from Deezer, a global music streaming service, confirming the critical importance of repetition modeling for sequential listening session recommendation. Along with this paper, we publicly release our proprietary dataset to foster future research in this field, as well as the source code of PISA to facilitate its future use.
This paper has been accepted for publication in the proceedings of the 18th ACM Conference on Recommender Systems (RecSys 2024).