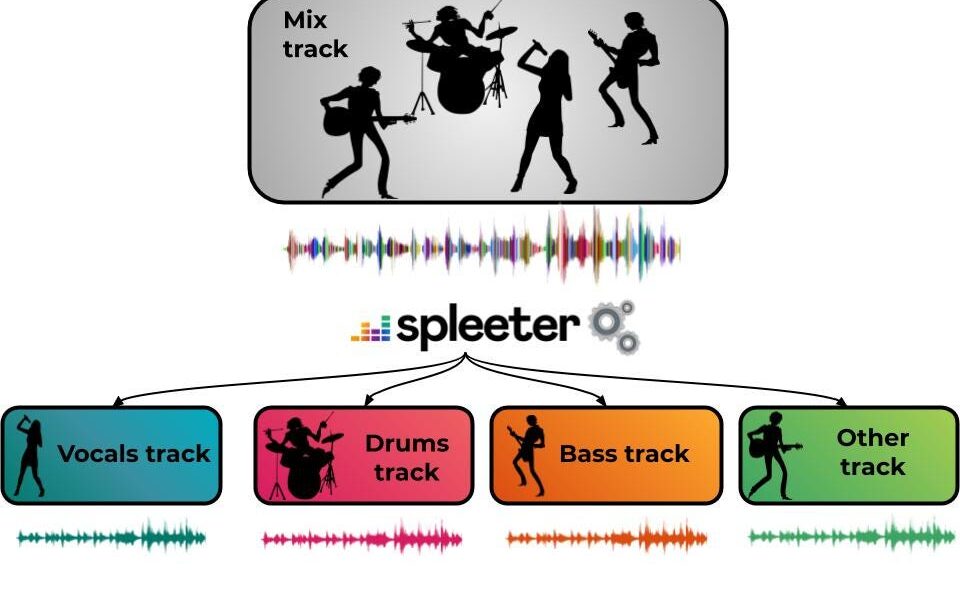



In a nutshell
We are releasing Spleeter to help the research community in Music Information Retrieval (MIR) leverage the power of a state-of-the-art source separation algorithm. It comes in the form of a Python Library based on Tensorflow, with pretrained models for 2, 4 and 5 stems separation. Spleeter will be presented and live-demoed at the 2019 ISMIR conference in Delft.
A brief overview of source separation
While not a broadly known topic, the problem of source separation has interested a large community of music signal researchers for a couple of decades now. It starts from a simple observation: music recordings are usually a mix of several individual instrument tracks (lead vocal, drums, bass, piano etc..). The task of music source separation is: given a mix can we recover these separate tracks (sometimes called stems)? This has many potential applications: think remixes, upmixing, active listening, educational purposes, but also pre-processing for other tasks such as transcription.
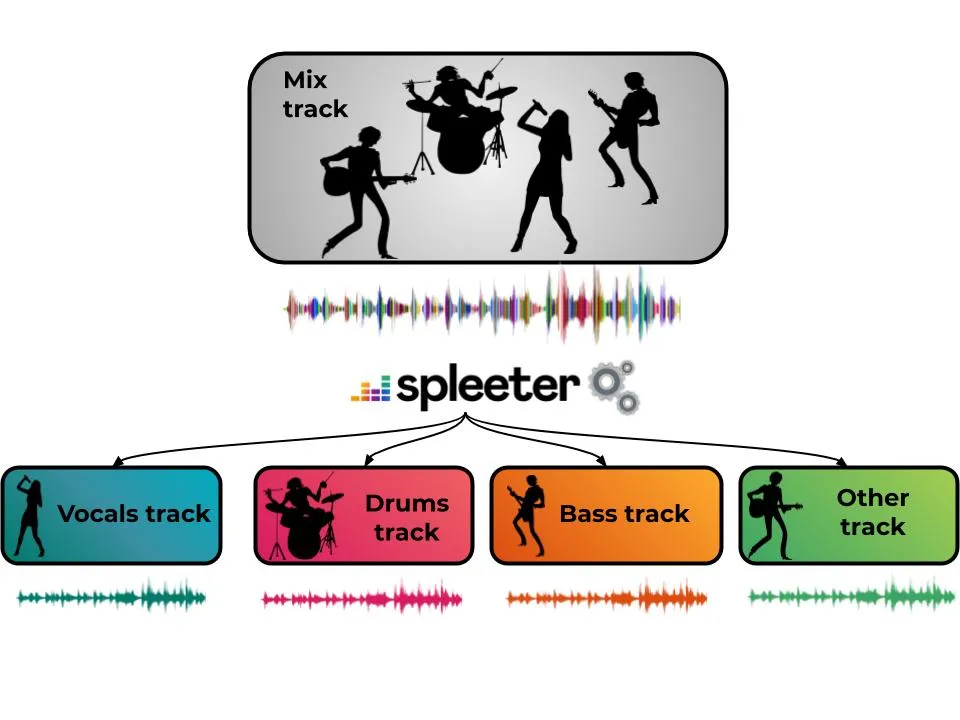
Interestingly, our brain is very good at isolating instruments. Just focus on one of the instrument of this track (say the lead vocal for instance) and you will be able to hear it quite distinctively from the others. Yet that’s not really separation, you still hear all the other parts. In many cases, it may not be possible to exactly recover the individual tracks that have been mixed together. The challenge is thus to approximate them the best we can, that is to say as close as possible to the originals without creating too much distortions.
For years, a lot of strategies have been explored, by dozens of brilliant research teams from all over the world. If you’re interested in this fascinating journey you should go read this literature overview, or this one. The pace of progress has recently made some giant leaps, mainly due to advances in machine learning methods. To keep track, people have been comparing their algorithm in international evaluation campaigns. That’s how we know that Spleeter performances match those of the best proposed algorithms.
Additionally, Spleeter is very fast. If you are running the GPU version you can expect separating 100x faster than real-time which makes it a good option to process large datasets.
What can I do with Spleeter ?
Quite a lot I’d say. If you’re a researcher working on Music Information Retrieval and have always considered that source separation artifacts made it unsuitable as a pre-processing step in your pipeline… Well, you should probably reconsider and try Spleeter. If you are a music hacker and want to build something awesome using Spleeter, then go ahead. Actually Spleeter is MIT-Licensed so you are really free to use it in any way you want. It goes without saying that if you plan to use Spleeter on copyrighted songs, make sure you get proper authorization from right owners beforehand.
How can I use Spleeter ?
Under the hood, Spleeter is a fairly complex and crafted engine but we’ve worked hard to make it really easy to use. The actual separation can be achieved with a single command line, and it should work on your laptop regardless of your Operating System. For more advanced users, there is a python API class called Separator that you can manipulate directly into your usual pipeline.
We’ve tried hard to come up with a thorough documentation. Don’t hesitate to give us feedback, point out issues or suggest improvement through the traditional github tools!
Why release Spleeter ?
Short answer: we use it for our research and think other might want too.
We’ve been working on source separation for a long time (and we already had a publication at ICASSP 2019). We have benchmarked Spleeter against Open-Unmix -another open-source model recently released by a research team from Inria- and reported slightly better performances with increased speed (note that the training dataset is not the same).
One of the hard limitations faced by MIR researchers is the lack of publicly available datasets due to copyright issues. Here at Deezer, we have access to a fairly large catalog that we’ve been leveraging to build Spleeter. Since we can not share this data, turning it into an accessible tool is a way for us to make our research reproducible by everyone. On a more ethical standpoint, we feel there should not be an unfair competition between researchers based on their access to copyrighted material or lack thereof.
Last but not least, training this kind of models requires a lot of time and energy. By doing it once and sharing the result, we hope to save others some trouble and resources.
A final word
Since we released Spleeter, we have received numerous feedback, most of them very positive and we’re thrilled to see all that attention given to our work. A few of these reactions may however be a little over-enthusiastic, so let’s just restate a few things. Spleeter is a neat tool, but in no way do we claim to have “solved” source separation. Hundreds of researchers and engineers working for decades have made the advances and built the tools on which Spleeter is based. It’s our contribution to a vivid, ever-growing and open ecosystem and hopefully something others will build upon too.
Finally, it’s worth pointing out that music mixing is a fine art and that mastering sound engineers are artists in their own rights. Obviously we do not intend to harm their work in any manner or affect anyone’s credit. When you use Spleeter, please do so responsibly.
That being said, happy hacking everyone!